star schema

What is a star schema?
In data warehousing, a star schema is a dimensional model for organizing data into a structure that helps to improve analytical query performance. A star schema is made up of two types of tables: fact and dimension. A fact table sits at the center of the model, surrounded by one or more dimension tables. The fact table contains quantitative information (facts) about a process, event or condition, along with foreign keys that reference the surrounding dimension tables. A star schema can include one or more dimension tables, which contain attributes that describe the facts.
The star schema is used in data warehouses and data marts to support analytics and business intelligence (BI) applications, as well as online analytical processing (OLAP) cubes. The schema's design helps to simplify and optimize the types of queries typical of these applications. These queries often attempt to answer critical business questions, although they often require large sets of data.
With a star schema, analysts can build queries that filter and group (slice and dice) the data by one or more dimensions and then aggregate the results at different levels of granularity. For example, a data analyst might build a query to answer questions such as "What were the total number of sales for male customers in Wisconsin for the month of June?" or "What were the average monthly and annual revenues for the Texas office from 2020 through 2023?"
The star schema gets its name from the way in which the fact table sits at the center of the logical design and the dimension tables branch out to form the points of the star.
What are the basic components of the star schema?
A star schema is made up of fact and dimension tables. Although the two types of tables contain related data when used in a single schema, they differ in how they're defined and the types of data they store. It is these differences that determine the table type, rather than the table being defined with a particular attribute that designates it as one type or the other.
The fact table lies at the heart of the star schema, providing a central focal point for organizing and querying the data. A fact table can include one or more of the following column types:
- Measures. A fact table usually contains at least one measure that quantifies the process, event or condition on which the fact table is based. Measures are typically numeric values that represent key business metrics, such as the number of units sold, wholesale cost per unit, total sales amount or percentage of profit. It is possible for a fact table to contain no measures, in which case, it is referred to as a factless fact table.
- Foreign keys. A fact table in a star schema must include at least one foreign key column, although it usually contains more. The foreign keys reference the dimension tables, thereby providing a structure for easily querying the data based on the dimensions' attributes. If there were no foreign keys, the schema would not be a star schema.
- Degenerate dimensions. A degenerate dimension is a column that is not a measure or foreign key but in some way provides additional information about the process, event or condition. For example, it might be an order number, line number or other type of information that can be useful when querying the data. A fact table can contain one or more degenerate dimensions, although it is not required to include any.
- Surrogate keys. A fact table is typically defined with some type of primary key. The primary key might be a simple surrogate key, in which case a column is added to the table for the key values (usually integers). If a surrogate key is not used, the primary key might be a degenerative dimension, a composite key made up multiple degenerative dimensions, or a composite key made up of the foreign key columns, which serve as their own natural key.
Figure 1 provides an overview of a star schema. In this case, the fact table is named Orders. It includes the Order ID column, a degenerate dimension that can also serve as the primary key. In addition, the table contains two measures: Order Profit and Order Quantity. The remaining columns are foreign keys that reference the schema's dimensions.
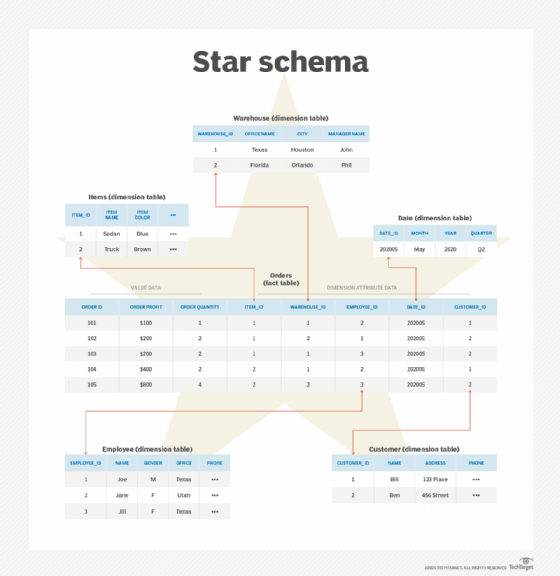
The dimension tables contain attributes that describe the facts in the fact table. In Figure 1, the dimension tables include the Warehouse, Items, Date, Employee and Customer tables. They provide the reference information needed to make sense of the fact data. In this way, analysts and other users can slice and dice the data in various ways to answer specific business questions.
A dimension table typically uses an integer surrogate key for its primary key, rather than a more complex natural key. Surrogate keys help to simplify the join operations between the fact table and dimension tables and make them more efficient. The remaining columns in a dimension table contain the attribute data that can be applied to the facts. For example, the Employee table includes the Name, Gender, Office and Phone columns. Each column describes some aspect of the Orders facts. The remaining column, Employee_id, serves as the table's surrogate key.
What sets the star schema apart from other dimensional models is that each dimension table is fully denormalized to support the type of read-intensive workloads typical of BI and analytics. This is in direct contrast to transactional workloads, which require highly normalized database structures to accommodate the workloads' continual read and write requests. These databases must adhere to the strict data integrity requirements of a transactional system.
When designing their star schemas, data architects should clearly define each table as either a fact table or dimension table, rather than trying to mix them together. They should also consider the required level of granularity. For example, they might choose to store only months and years in the date dimension, rather than individual dates, in which case, the dimension's date granularity will be months. However, if they decide to store the dates as well, the granularity will be those individual days. The dimensions' granularity affects the level at which the fact data can be sliced.
What is the difference between a snowflake schema and a star schema?
Query performance is often better with a star schema over other dimensional models because the dimension tables are denormalized, eliminating many of the costly join operations that come with the other models. In a star schema, there is only one level of dimension tables, and all foreign key relationships are defined between the fact table and the dimensions. A query never needs to join tables beyond the single layer of dimension tables, resulting in better performance than if the dimension tables were normalized.
This denormalized structure can also mean that the dimension tables contain a great deal of redundant data. As a result, they take up more disk space than would be needed for a normalized structure, and they're at greater risk for data integrity issues. The star schema can also make it difficult to define queries with complex dimensional relationships, such as hierarchical or many-to-many relationships. Because of these issues, some data architects adopt a snowflake schema in certain situations, rather than the star schema.
A snowflake schema can be thought of as a variation of the star schema. Like the star schema, the snowflake schema contains a central fact table surrounded by dimensions. The big difference is that the dimensions are normalized, which means they might reference other dimensions, branching out into a snowflake pattern.
The normalization in a snowflake schema is often based on cardinality, which refers to the number of unique values relative to the number of rows. Attributes with low cardinality are pushed out into separate dimensions, with foreign keys pointing from the parent dimension to the child dimensions.
Figure 2 shows a snowflake schema, with the Orders fact table once again at the center. The schema is similar to the star schema in the previous example, except that now several dimensions have been normalized.
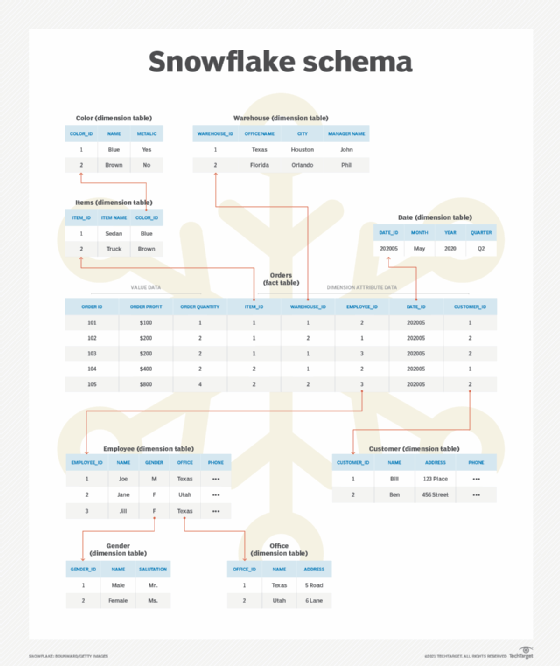
One of the dimensions that has been normalized is Items. In the star schema, the dimension includes all the values for the Item Color column directly within the table, which can mean a significant amount of redundant data. In the snowflake schema, the column is named Color_id, and it is a foreign key that references the primary key of the new Color dimension.
The Color dimension eliminates much of the redundant data because now there is only one row per color. However, it also means that queries are more complex because they must join an additional table. This approach can cause performance to suffer, depending on the number of rows. If a fact table contains millions of rows, every extra join can come at a steep price.
What are the main benefits of a star schema?
The star schema is used extensively in data warehouses and data marts because of the important benefits it offers:
- The star schema is simpler to design, maintain and understand than other schema models.
- Read queries are much faster because the schema is denormalized, avoiding many of the expensive joins required by other schema models.
- The denormalized structure makes it easier to create, understand and update the queries because of the reduction in joins.
- The star schema offers easy integration with OLAP systems and data cubes.
What are the main disadvantages of a star schema?
Despite the benefits of the star schema, it is not without its challenges:
- The star schema requires more storage space than other schema models because of all the redundant data, which can become quite significant.
- The schema does not enforce data integrity like a normalized structure, putting the data at risk. This, in turn, can affect the quality of the analytics and reports that rely on the data.
- Because the dimension tables are denormalized, data maintenance can be more difficult.
- The schema makes it more difficult to define queries with complex dimensional relationships, such as hierarchies or many-to-many relationships.
- The star schema is less flexible than other schema models and might not scale as easily as other models.
Star schema use cases
The star schema is most commonly used in data warehouses and data marts to support analytics and BI applications, which often rely on historical data. The schemas are optimized for querying large amounts of data that needs to be filtered, grouped and aggregated.
Data might be imported into a star schema's tables in different ways. For example, a database team might set up an extract, transform and load (ETL) operation that imports data in near real time from a relational database that supports a transactional application. On the other hand, the data might be imported in chunks through batch operations that are executed at scheduled intervals. Regardless of how data is imported, it is typically subject to an ETL process.
The star schema is generally not a good fit for applications such as online transaction processing. The schema's denormalized structure means that the data must be carefully processed and verified at all times to ensure the data's integrity and reliability. Even then, that integrity cannot always be guaranteed.
A normalized data structure already includes many of the checks and balances necessary to maintain data quality, without the extra effort required by a denormalized structure. Even with the extra verification, the denormalized structure is still susceptible to data abnormalities, which could be disastrous in a live order fulfillment system. The star schema is best suited for data warehouses and data marts and the workloads they support.
Learn about 8 types of database keys including primary, super, foreign and candidate keys, what they're used for and how they work. Evaluate data warehouse deployment options and use cases and explore the differences between dimension tables vs. fact tables. Check out the pros and cons of on-premises vs. cloud data warehouses, read about data integration challenges and how to overcome them, and see how to develop an enterprise data strategy.






