Data orchestration vendor Alluxio is updating its namesake platform to version 2.2, integrating new data catalog and transformation services to help organizations improve data management.
Alluxio 2.2 became generally available today in an open source community edition, as well as an enterprise edition. The vendor, based in San Mateo, Calif., is grouping its new capabilities under the name Structured Data Service and extends the existing Alluxio platform capabilities to better enable data pipelines. Data catalog functionality, in particular, has become an increasingly necessary capability for organizations as they attempt to make disparate sets of data available to the business for analytics and business intelligence use cases.
Paige Bartley, an analyst at 451 Research, said that given the trend toward multi-cloud and hybrid architecture, efficiency of decoupled compute and storage is not always easy to optimize.
"Increasingly, data is physically stored separately from where compute takes place," Bartley said. "While this provides flexibility, it can also result in certain inefficiencies."
Bartley added that Alluxio Structured Data Service aims to tackle this challenge, with the goal of abstraction. She said that by utilizing a structured data catalog to provide a more unified metadata layer, queries can be better optimized, helping organizations in their data insight initiatives, across varying IT architecture.
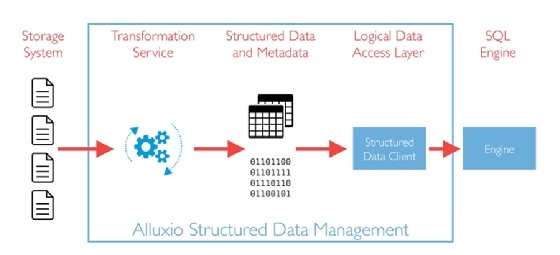
Alluxio's data orchestration approach aims to help manage the flow of data from a storage system to connect with a SQL engine for queries and analysis.
Alluxio data catalog looks to improve data orchestration
According to Steven Mih, CEO of Alluxio, there has been a mismatch between data storage and SQL query frameworks like Apache Spark and Presto. He explained that SQL query frameworks rely on database schema, rows and tables, while data storage is typically just about providing the ability to retain data at the lowest cost per bit. Alluxio is intended to be deployed as a layer between data storage and SQL frameworks to help connect one to the other, enabling data orchestration.
Increasingly, data is physically stored separately from where compute takes place. While this provides flexibility, it can also result in certain inefficiencies.
Paige BartleyAnalyst, 451 Research
Mih said his company already had multiple components to enable data orchestration, including data management and caching capabilities to help move data from one silo to another. With the new data catalog, it's now possible to also connect to metastores of data such as Apache Hive or AWS Glue.
"With Alluxio data catalog now, you just connect to Alluxio and the catalog connects to all the data," Mih said.
Aseem Rastogi, vice president of engineering at Alluxio, said the data catalog reflects what is available in metadata stores and ensures that they remain synchronized. As such, he added that any SQL query will get access to the latest data via Alluxio, the same as if it were directly connected to the metadata.
Transformation service makes data more usable
Alluxio is also adding a data transformation service. According to Mih, the service can transform data from whatever format it was stored in to a format usable for SQL frameworks to more easily query and analyze.
The transformation service comprises several components, including a service to coalesce smaller data files into larger files for more optimized compute. There is also a capability to deal with CSV files, which is commonly used for spreadsheets. Mih said the transform service can convert CSV files into the Parquet format, which is well suited for SQL query frameworks and business analytics.
The idea of transforming data is commonly associated with ETL technology, though that's not how Alluxio is positioning its service. Rastogi said that with a traditional ETL, data is transformed based on business logic, while Alluxio's focus is on optimization for compute.
Rastogi said the data orchestration platform vendor will continue to optimize data access and availability capabilities in future releases.
"The idea is to be able to make the data available when it's required for the compute frameworks and the right amount of data," Rastogi said.