
Getty Images/iStockphoto
7 data quality best practices to improve data performance
Data quality is essential to operate a successful data pipeline and enable data-driven decision-making. These seven data quality best practices can help improve performance.

Data quality is essential for any analysis or business intelligence. Employing best practices lets organizations address issues that become even more critical and challenging as teams build a data analytics pipeline.
Subtle problems can get magnified by improved automation and increased data aggregation. Teams may also struggle to sort out the precise cause of issues buried within complex data pipelines.
"Data is often viewed as an organization's most valuable asset," said Alexander Wurm, analyst at Nucleus Research. "However, this is not always true. Poor data quality can taint business outcomes with inaccurate information and negatively impact operations rather than improving them."
Enterprises can set up practices to track data lineage, ensure data quality and protect against counterproductive data.
Key metrics of data quality
There are many aspects of data quality teams need to address. Teams should start with core attributes of high and low data quality, said Terri Sage, CTO of 1010data, a provider of analytical intelligence to the financial, retail, and consumer markets. These must reflect characteristics such as validity, accuracy, completeness, relevance, uniformity and consistency.
Teams that automate these measurements can determine when their efforts are paying off. Additionally, these metrics can also help teams correlate the cost of interventions, tools or processes with their effect on data quality.
Why data quality is important for the data analytics pipeline
Data quality is essential to the data analytics and data science pipeline. Low-quality data may lead to bad decisions, such as spending money on the wrong things, Sage said. Incorrect or invalid data can impact operations, such as falsely detecting a cyber security incident.
High data quality is measured by how well it has been deduplicated, corrected and validated and whether it has the correct key observations. High-quality data leads to better decisions and outcomes based on the fit for their intended purpose.
In contrast, bad data can reduce customer trust and lower consumer confidence. Correcting data riddled with errors also consumes valuable time and resources.
"An enterprise with poor-quality data may be making ill-judged business decisions that could lead to lost sales opportunities or lost customers," said Radhakrishnan Rajagopalan, global head for technology services at Mindtree, an IT consultancy.
How pipeline can affect data quality
There are various ways the data analytics pipeline impacts data quality. One of the biggest issues Sujoy Paul -- vice president of data engineering and data science at Avalara, a tax automation platform -- faces is the quality of data they are aggregating.
Two factors make data quality challenging as they grow their data aggregation pipeline.
One issue is potentially losing or duplicating data during transfer from source systems to data lakes and data warehouses. For example, memory issues with cloud data pipeline technologies and data queuing mechanisms often cause result in small batches of lost transactions.
The second issue is unpredictable variations in the source systems leading to significant data quality issues in destination systems. Many potential problems lead to unpredictable data from source systems, but changes in data models, including small changes to data types, can cause significant variations in destination systems.
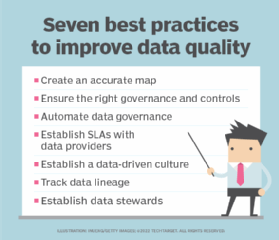
Here are seven data quality best practices to improve performance:
1. Create an accurate map
Teams should curate an accurate, digestible picture of data assets and pipelines, their quality scores, and detailed data lineage analysis, said Danny Sandwell, director of product marketing at Quest Software, an IT management software provider.
This map identifies where data comes from and how it may change in transit. Many teams use data transformation to streamline integration. However, many advanced analytics require raw data to provide sufficient accuracy and detail. Modern data catalogs that harvest metadata, analyze data lineage, and perform impact analysis can help automate this process.
2. Ensure the right governance and controls
Data management and governance measures are critical, said Rajagopalan. Good governance starts with ensuring an organization can onboard various data sources and formats in real-time while maintaining quality without duplication.
It is also essential to have a metadata storage strategy that lets users locate datasets easily. The governance framework should also protect any personally identifiable data to stay in compliance with privacy laws.
Governance issues are coming to a head for many organizations that filled up data lakes without putting in the right structure of governance measures, Rajagopalan said. This resulted in poor data quality and higher interest in data lakehouses, which use some of the best features of data warehouses, such as formalized governance controls. They are cost-efficient and open, such as a data lake.
"Companies that are currently using data lakes should determine whether it is compromising their data quality and whether a data lakehouse is a better approach," he said.
3. Automate data governance
Data governance approaches fail when they rely on too many manual processes to measure inventory and remediate data, said Brian Platz, CEO and co-founder of Fluree, a blockchain database platform. These manual approaches cannot operate at an appropriate scale and speed with increasing data volumes.
Organizations should automate the data governance process with machine learning to speed up the analytics pipeline while also mitigating the risk of error. Enterprises can significantly reduce the IT overhead of a data management transformation by automating this governance process. This can encourage data quality at scale.
4. Establish SLAs with data providers
It's helpful to set up service level agreements (SLA) with data providers, said Tobias Pohl, CEO of CELUS, an electronic engineering automation platform. These should include clear definitions of data quality, sources and formats. Pohl's team set up data custodians and stewards and a data management framework to ensure that subject matter experts interpret data inputs before applying transformations and loading the data into their systems.
"There needs to be monitoring and alerts set up to ensure the quality of incoming data," he said.
5. Establish a data-driven culture
A data-driven culture that emphasizes observation, discussion, and remediation across the enterprise is crucial.
"This eliminates siloes and democratizes the data for different departments and business use cases," said Jeff Brown, team lead for business intelligence projects at Syntax, a managed service provider.
6. Track data lineage
Modern analytics pipelines are complex, with various data sources, transformations, and technology. When a data quality issue occurs, organizations often spend numerous IT resources to identify the cause before its impact spreads. As a result, many organizations are adopting data lineage solutions to rapidly identify the root cause and downstream impact of poor data quality.
Organizations are increasingly recognizing the importance of data lineage and cataloging to ensure data quality, Wurm said. At the same time, organizations have the most flexibility before implementing the solution, so prioritize a data lineage roadmap to better address future challenges early in the process.
7. Establish data stewards
Algorithms can't remediate all data quality issues. Data stewards can give a thoughtful eye to the data and correct any outstanding errors, said Christophe Antoine, vice president of global solutions engineering at Talend. This should only take a few minutes and will significantly increase your data quality and corresponding analytics.
A data steward should be appointed to look after all data at the departmental level, but it's essential for the entire business to own the data and not IT alone. The challenge is that enterprises cannot get there through technology alone. A data-driven culture requires buy-in and support across all levels of the business.







