
Getty Images
Tips for planning a machine learning architecture
When planning a machine learning architecture, organizations must consider factors such as performance, cost and scalability. Review necessary components and best practices.

Planning a machine learning architecture can be challenging because it requires balancing a range of priorities, including performance, cost and scalability.
Although these considerations apply to many types of architectures, ML environments often have specific needs, such as the ability to access bare-metal hardware. These special requirements add an extra layer of difficulty to ML architecture design.
With these challenges in mind, organizations have much to consider when planning an ML architecture. Because an ML architecture comprises all the tools and applications needed for an ML workload, each organization's setup will be complex and unique to its IT environment.
When determining the specifics of your setup, it's essential to consider the goals of your ML architecture in areas such as performance, cost and security. By following these best practices for ML architecture design, you can build an efficient, well-structured system that can effectively balance competing organizational priorities.
What is an ML architecture?
An ML architecture is the complete set of components that power an ML workload.
The specific elements vary by environment. But core parts of an ML architecture typically include the following:
- Data sources. These provide the data that ML models train on. Some ML architectures draw on data that already exists, such as publicly available internet content, whereas others rely on unique, original data sources.
- Data quality management tools. These ensure that data meets the accuracy and completeness requirements of ML models.
- Data pipelines. These move data from its source to the models that need to ingest it.
- Data training processes. These facilitate the process of building and refining models using the available data.
- ML applications. These generate insights using the models trained on the architecture.
- Compute and storage infrastructure. This hosts all the components.
- Orchestration tooling. This is used to manage the various components of the ML architecture and unify them into a coherent ML pipeline.
All these components make ML architectures more complex than many other types of IT architectures. For example, the architecture that powers a basic web application is relatively simple: a web server application, a server to host it and potentially a database to store website data. It's a simpler architecture because it doesn't have to support processes such as data ingestion or model training.
In addition, ML architectures can be complex because ML workloads require special types of infrastructure and resources. For example, they often need access to bare-metal infrastructure to use GPUs. They also might require orchestrators that are purpose-built for ML, such as Apache Airflow.
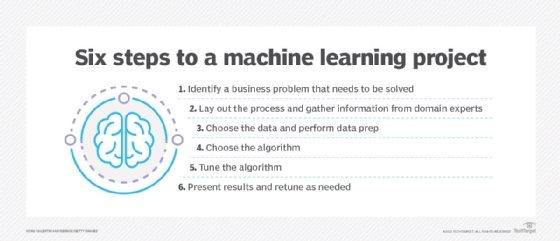
5 considerations when planning an ML architecture
In addition to identifying which components are necessary for a particular workload, ML architects must also consider goals related to ML workload outcomes and business priorities. The following are some of the top considerations.
1. Performance
Some ML workloads require higher levels of performance than others. If a team is under pressure to deliver models on a tight timeline, training might need to happen fast. Generally, this means that the ML architecture will require more compute resources to speed up training.
2. Scalability
Some ML workloads grow over time due to factors such as an increase in the volume of training data or the need to deploy multiple variations of the same model. If the ability to handle increased ML workload capacity is a priority, the ML architecture should be capable of scaling up.
Likewise, some ML workloads might need to scale down. For example, a team might abandon some models, requiring less infrastructure to support them. In this case, the ability to scale down the environment is important to avoid wasting money on infrastructure that's no longer needed.
3. ML lifecycle duration
ML architecture design should reflect how long an ML workload needs to be operational. In some cases, ML models and apps might be deployed for a specific, one-time purpose. Others might need to operate indefinitely.
A related factor to consider is how often models require retraining. Will the ML team train the model once and then run it for years, or will it be updated multiple times a year? The latter case will require an ML architecture that supports recurring model training.
4. Cost
Cost is another major consideration for ML architecture design. Although organizations don't want to overpay for ML infrastructure or services, it's equally important not to underinvest in requirements. Doing so could result in development delays or poor performance.
5. Security and compliance
Depending on the sensitivity of the data used for ML training, as well as any compliance requirements that govern data or models, specialized infrastructure might be necessary to minimize security and data privacy risks.
6 best practices for ML architecture design
Because every ML workload is different, there is no one-size-fits-all approach to designing an ML architecture. But in most cases, the following best practices are helpful for planning an architecture that provides the best overall balance among performance, scalability and cost.
1. Use discounted infrastructure
In some cases, it's possible to lower costs without compromising performance by taking advantage of discounts on infrastructure. For example, using AWS Reserved Instances servers can save substantial amounts of money on ML compute costs. However, this option is only a good fit for teams that will be operating ML models for a fixed period and can commit to the reservation period.
2. Consider private clouds
Although all major public clouds offer bare-metal server instances and instances equipped with GPUs, it's more cost-effective in some cases to purchase servers and build a private cloud environment for ML workloads. Private clouds can also help address the data security and compliance challenges associated with some ML workloads because they eliminate the need to expose sensitive data to third-party infrastructure.
Using a private cloud is an especially attractive option for organizations that plan to use the ML infrastructure on an ongoing basis. But for those that will only be training a model once, renting servers in the cloud might be a more cost-effective approach.
3. Use containers
Deploying ML workloads using containers can increase scalability and flexibility compared with running apps and services directly on servers. Containers help teams redeploy software more quickly.
In addition, when paired with an orchestration platform such as Kubernetes, containers can distribute workloads across clusters of servers. Organizations can then add or remove servers from the clusters depending on workload scalability needs.
4. Consider open source
The burgeoning ML ecosystem includes a variety of free and open source tools as well as commercial options for orchestrating and managing ML workloads.
For organizations looking to save money, open source tools can help. However, open source options often require more effort to deploy, so make sure that team members have the necessary expertise before choosing this route.
5. Look for publicly available data
Organizations can produce training data for ML models either by generating it themselves or by paying for private data. Both approaches require effort and money. If there is freely available data that can be used for training instead, consider that route to save money without sacrificing performance.
6. Invest in data quality
The higher the quality of the training data, the faster and more efficient ML training tends to be. Data quality issues can undercut model effectiveness, leading to more time spent tweaking and retraining.
For that reason, make data quality a priority within your ML architecture. Implement data quality checks that can validate your data sources and address data quality issues as early as possible within your ML pipeline. This could require you to invest more resources in data quality, but you'll reap the rewards in the form of more efficient processes later in the pipeline.
Chris Tozzi is a freelance writer, research adviser, and professor of IT and society who has previously worked as a journalist and Linux systems administrator.







