As businesses race to capitalize on the promises of AI in the wake of ChatGPT's launch, strategies to move machine learning software from idea to reality are becoming essential.
Although the past decade saw staggering advances in the capabilities of machine learning models, AI hype has reached new heights since the explosion of ChatGPT and other large language models. But without effective strategies for deploying and managing ML software, businesses might not realize AI's full potential.
Running ML models in production requires striking a tricky balance between ensuring model performance and scaling software to meet increasing demand. Even ChatGPT creator OpenAI isn't exempt; skyrocketing traffic has made server capacity and outages recurring issues since the chatbot's launch.
Enter MLOps: an approach at the intersection of data science, ML engineering and DevOps. Although the MLOps landscape remains in flux, the field seeks to address the challenges that arise when taking excitement around AI beyond the theoretical.
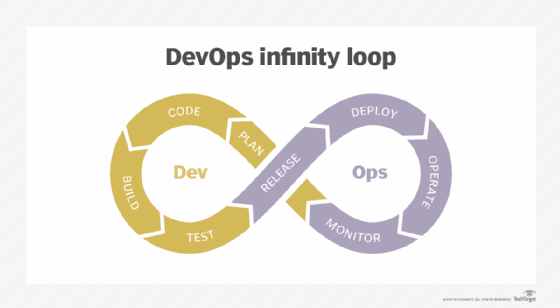
DevOps vs. MLOps
The term MLOps draws on the more familiar DevOps methodology, whose name combines software development and IT operations. Like DevOps, MLOps is an approach to producing software that involves a combination of tooling, strategy and culture.
ML software shares many similarities with its non-ML counterparts. Typical performance metrics like latency and load are still relevant with AI software -- sometimes even more so, given that large models can be highly computationally intensive.
Likewise, designing, deploying and operating ML models requires collaboration across teams. Just as the originators of the DevOps philosophy hoped to reduce conflict between software developers and IT ops teams, MLOps aims to promote collaboration between these groups as well as data scientists and data engineers.
In fact, some experts argue that MLOps shouldn't be viewed as distinct from DevOps at all: "I think MLOps is an extension of DevOps," said Mikiko Bazeley, head of MLOps at virtual feature store Featureform. "I don't think it's a separate category."
Piotr Niedzwiedz, CEO of MLOps startup Neptune.ai, shared a similar sentiment in an October 2022 blog post. "At the end of the day, we are all just delivering software here," Niedzwiedz wrote. "A special type of software with ML in it but software nonetheless."
Meeting the specific challenges of running AI at scale
That said, ML and AI do differ from traditional software in some important ways. ML pipelines involve several stages that aren't present in the traditional software development lifecycle, especially before and after models enter production.
In addition to the more familiar phases of the DevOps cycle, ML software requires additional stages, such as data ingestion and model retraining.
The importance of data quantity and quality is one of the biggest factors that differentiates AI from non-AI software. "The model is driven by the code, which is driven by the data," Bazeley said, "which is totally not the way traditional software products work."
When creating an ML model, data scientists must gather, clean, transform and prepare their data for the model. After the model is developed, it's then trained and validated on data subsets, checking metrics like accuracy, precision and recall.
These stages can themselves be highly challenging and time consuming. But using AI to solve a business problem requires actually putting the working model into production, and serving and deploying an ML model is very different from building one.
"Think about what's needed in order to deploy," said Gilad Shaham, director of product management at MLOps platform Iguazio, in a recent talk at the conference AI at Scale. "The question of how to package, how to secure everything, how to test, CI/CD, automation, monitoring, versioning -- a lot of moving parts that you don't necessarily want the data scientists to have to do."
Some of these are standard DevOps challenges, like integrating with existing applications and scaling software as demand increases. But even familiar issues can be more complex in an MLOps context.
Other challenges are more specific to AI. Producing and operating ML software requires communicating with a larger team that includes data scientists and ML engineers, as well as deciding when and how to retrain models as new data comes in.
As an example of the latter, Shaham described an ML application that uses the average amount a customer spent in the last three months as a model feature. "When you get to deployment, and especially in real-time deployments, how does one access that feature?" Shaham said.
Common points of failure in operationalizing AI
At a high level, any organization deploying ML models will go through a few of the same stages: manual design and development, followed by automation, and finally model monitoring, retraining and analysis.
To date, MLOps tools and platforms have largely focused on building repeatable processes and automations for these stages. "Getting the data, training and deploying the model, setting up monitoring -- the whole thing needs to be as automatic as possible," Shaham said.
But apart from those broad similarities, the MLOps journey can look very different from organization to organization. Companies that never intend to grow beyond several hundred employees, for example, will likely not require certain infrastructure capabilities that a large enterprise needs.
The post-deployment stages are where many companies looking to adopt ML get tripped up. Overall, there are simply many more ways for ML models to go wrong compared with traditional software, and the consequences can be more significant when they do.
"The hard lesson that many companies learn between getting their models from a proof-of-concept state to the real world is that there's this additional set of requirements that come after you've already developed the first model," said Eric Landau, CEO of active learning software company Encord, in another AI at Scale session.
On a practical level, deploying, maintaining and improving an ML model requires extensive tooling, IT infrastructure and collaboration across a wide range of teams and roles. "Most of the failures are on the production side: how to take that model and make it part of a pipeline and scale it up," Shaham said.
This problem is complicated by the tradeoff between model training and performance. Because data set processing and feature engineering can impact latency, those responsible for various stages of an MLOps pipeline must decide how much effort to sink into these processes.
At times, an ML model may run without issue from a performance perspective, but a change in data distribution leads to degraded accuracy and precision. Thus, in some cases, "when ML software goes wrong, it technically worked," Bazeley said. "But there's behavior or there's an impact that maybe wasn't surfaced early on."
Training-serving skew refers to a phenomenon where a model performs well in training but is less effective when it's deployed to production. For example, if a recommender system that uses categorical variables encounters a category in the production data that the model wasn't trained on, the system may not be able to handle it.
When we think of an ML model, is it working, or is it doing what we want it to?
Mikiko BazeleyHead of MLOps at Featureform
In his AI at Scale talk, Landau discussed a use case from Encord's experience, in which a company designed an ML-powered parking management system. The system worked well for the initial location of Boston, but when the company sought to expand to new cities, the model struggled to keep up.
"They realized -- oh my, the same model that we worked with in Boston, it doesn't work as well in Santa Monica and Seattle and Minnesota," Landau said. "There were certain subsets and use cases where it just wasn't really doing very well."
And this issue goes beyond the technical. When it comes to AI, the stakes are simply much higher than with traditional software, Bazeley pointed out. ML models' unpredictable performance on new data can raise big-picture ethical concerns -- and even a model that's accurate and precise on paper could still be problematic in other, deeply damaging ways.
"It could also be that [the model] is being unfortunately accurate and precise in, let's say, mimicking racist conversations," Bazeley said. "When we think of an ML model, is it working, or is it doing what we want it to? I think it begs a deeper question about what would we feel is acceptable behavior."
The future of AI and MLOps
Unlike DevOps, MLOps is still an emerging field. But as more companies seek to use AI in their applications and software, the need for a well-defined MLOps framework is growing.
In a 2022 Deloitte report, nearly all respondents described AI as critical to their organization's success over the next five years. But half reported problems with maintenance or ongoing support after initial launch, and 41% said their organization didn't have sufficient technical skills when it came to AI and ML.
Ultimately, "the maturity around how to build ML stacks just isn't quite there yet, including people knowing what to prioritize very early on," Bazeley said. "There's going to be a lot of confusion going forward."
Evaluating whether to adopt AI and MLOps
This means that it's important for organizations considering adopting AI and ML to ask whether there's a genuine business need in mind or if they're simply jumping onto a trend.
Access to ChatGPT and other large language models, for example, has greatly reduced the barriers to using generative AI. This opens up exciting opportunities for new use cases, especially among those who weren't previously able to take advantage of these technologies.
But at the same time, it's important to think through whether the organization has the resources and need to use AI and ML. When it comes to implementing generative AI, "[companies] need to have an actual product and business model around it," Bazeley said.
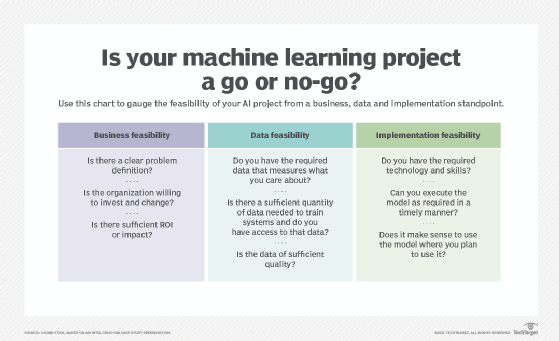
There are several factors to consider when evaluating a possible ML implementation for your organization, including business needs, data availability and technical resources.
Any companies seeking to implement a product with the ChatGPT API, for instance, will still need to serve and deploy that software on their infrastructure. At a higher level, they'll also need to differentiate themselves from the many competitors now also using generative AI -- for example, by building up proprietary data assets.
"This is the gap between that's neat -- maybe they had a proof-of-concept model that might do a good job in a demonstration to investors," Landau said, "and that's useful -- something that many people can use consistently in an application over and over. And because AI technology is so new, there will just naturally be fewer companies on the right side of the scale."
In addition to building technical knowledge on the various stages of the MLOps pipeline, successfully operationalizing AI requires collaboration that bridges the business-IT gap. In many organizations, product thinking is pushed over to the business side or product manager, with engineers viewing the technical aspects as their only responsibility.
Combined with increasingly narrow specializations within technical roles, "you see less and less people serving as bridges between the different worlds," Bazeley said.
Supporting creativity and innovation in AI development
Successfully implementing AI in production might also require accepting that ML experiments entail a certain level of risk -- including the fairly mundane risk of running analyses that aren't ultimately profitable.
In a recent Open Data Science survey of ML practitioners, respondents reported that less than half of models in their organizations were ever deployed to a production environment. Often cited as indicative of the failure of ML models, this low success rate can discourage businesses from investing in such projects, but such mindsets might be the wrong way to approach AI.
"What's the balance between supporting the creative spirit of data science," Bazeley asked, "while also making sure that [a model] is well tested and well structured before pushing to production?"
Rather than viewing any model that isn't deployed as a failure, businesses should keep in mind the reality that some analyses simply don't result in useful findings. To make progress and develop truly innovative software, organizations must continue to encourage creativity and experimentation, even in the face of projects that don't pan out as hoped.