How to implement a risk-based security strategy: 5 steps
Making the move from compliance-based to risk-based security helps organizations prioritize threats using systematic assessment and strategic planning.

Merely conforming to cybersecurity standards, such as ISO/IEC 27001, or complying with regulatory requirements, such as PCI DSS, won't automatically make an enterprise's security complete, effective or economical. Meeting a standardized control baseline might check compliance boxes, but creating a strong risk-based strategy, building a resilient operating environment and hardening against evolving cyberthreats requires more.
This gap -- the difference between the bare minimum and a strategic, formalized, resilience-based program -- is what risk-based security is all about. A risk-based approach incorporates information about the organization -- its goals, critical assets, context, threats -- into security planning. It ensures resources are used optimally, context-specific circumstances are accounted for, and that real threats tie directly to deployed countermeasures.
Let's look at what a risk-based security strategy involves and five steps security practitioners should follow when developing their plan.
What is risk-based security?
Security practitioners know that risk is a function of two factors:
- Impact. How bad a given outcome will be.
- Likelihood. The probability of that outcome happening.
A risk-based security program is one that accounts for both elements in its scope and planning: from control decisions and governance to program management and budgetary choices -- and everything in between.
On the surface, accounting for risk in a security program sounds obvious. In practice, it's rarely the default approach. Many organizations build their security programs by aligning to specific control sets rather than actual risk conditions. By design, compliance frameworks focus on whether given controls exist instead of whether they're warranted, efficient or aligned with actual circumstances.
Risk-based is often not the default because it requires more information and planning than just focusing on a stock catalog of controls. At a minimum, it requires knowledge of the following:
- Threats. Understanding who might attack the organization, their motivation and how they might do so.
- Vulnerabilities. Understanding the susceptibility of the environment to harm, from IT systems to operational technology.
- Assets. Understanding how assets support the business to accurately assess impact.
- Relative criticality. Understanding which assets are critical.
- Risk appetite. Understanding what the organization views as an acceptable risk tolerance.
Many organizations don't have these details. Or if they do, they know them only at the most basic level. Obtaining this information is only the first step. The information then needs to be systematically analyzed to support actionable decision-making.
Though difficult, there are significant benefits to doing this:
- Accounting for security outcomes lets organizations develop practical, realistic goals that support the organizational mission.
- Accounting for resource use enables more efficient investment and budget utilization.
- Accounting for threats and vulnerabilities means better performance at preventing cyberattacks and data breaches and realizing that noncompliance is itself a risk, too.
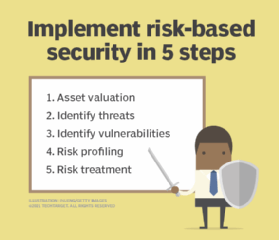
A risk-based security program takes work but is not necessarily difficult to set up. There are five key steps to implementing a risk-based security program that take higher time investment on the front end, but the rewards -- both in cost and time savings -- more than make up for it over the long term.
Step 1. Asset valuation
The first step is to understand the value of organizational assets. To do this, practitioners must know two things:
- What assets exist. This involves maintaining a complete, accurate and current inventory of all assets, including technology and data assets.
- The value of those assets. This means understanding the importance of the assets to the organization -- not just their replacement cost. The business criticalities of processes that assets support are not always equivalent. To understand the value, assess assets in the context of who uses them, what business processes they support, replacement costs, operational and business impacts of downtime, and so forth.
There is significant overlap between understanding asset criticality for risk assessment and doing so for business continuity. In fact, one productive technique is to combine the asset discovery and inventorying phases of risk assessment with business impact assessments, just as teams might do in furtherance of business continuity planning.
Step 2. Identify threats
In addition to understanding assets, practitioners also need to know how those assets can be attacked. This means realizing who -- or what -- could disrupt, impact or otherwise compromise those assets.
Identify who might want to steal or damage the assets, as well as why and how they might do it. This could include competitors, hostile nations, disgruntled employees or clients, terrorists and activists, and nonhostile threats, such as untrained or negligent employees. Also, consider the threat of natural disasters, such as floods, fires and tornadoes. Lastly, factor in nonenvironmental and nonintentional situations, including pandemics or geopolitical upheavals.
Assign each identified threat a threat level based on its likelihood of occurring. This requires input from business teams to add sector-specific knowledge to the security team's own threat assessments. Consider incorporating additional data, such as commercial threat intelligence or other information about the threat landscape.
Step 3. Identify vulnerabilities
A vulnerability is a weakness that can be exploited to steal, damage or otherwise negatively affect key assets. For an unwanted security outcome to occur, practitioners need two things: an actor -- e.g., a hacker, a natural disaster, etc. -- and a pathway for that actor to affect the enterprise. Since both need to be present for an unwanted outcome to occur, practitioners need to analyze both.
During this step, identify the vulnerabilities in the business environment. This enables practitioners to assess which threats are most germane to the company and to select the optimal controls to mitigate these specific threats. Consider using the following tools:
- Penetration testing and vulnerability scanning tools to identify software and network vulnerabilities.
- Threat modeling to map application issues.
- Configuration or patch management tools to find unpatched or end-of-life systems.
Additionally, account for physical vulnerabilities. Are perimeters secure and patrolled? Are fire extinguishers regularly checked? Are backup generators tested? Also consider vulnerabilities associated with employees, contractors and suppliers, including their susceptibility to social engineering attacks. Once again, collaborate with business teams to find and account for vulnerabilities specific to business processes in use.
Step 4. Risk profiling
After identifying the organization's assets, threats and vulnerabilities, begin risk profiling. This process evaluates existing controls and safeguards and measures risk for each asset-threat-vulnerability combination. Practitioners should systematically assess each asset for susceptibility to each threat using the vulnerabilities to guide how likely each is.
Do this formally or informally, quantitatively or qualitatively. There are hundreds of approaches to choose from, including the following:
- The Factor Analysis of Information Risk model.
- NIST Special Publication 800-30: Guide for Conducting Risk Assessments, in particular, Appendix I: Risk Determination.
- ISO 31000: Risk management -- Guidelines.
Base scores on the threat level and the impact on the organization should the risk occur. Consider using a qualitative approach to score each potential outcome across a scale of low, medium and high based on likelihood and impact. Or use economic calculations -- e.g., annualized loss expectancy. It's less important how practitioners do it than that they do it.
Read more on network security risk ratings.
Step 5. Risk treatment and remediation
The last and arguably most important step is to address the problems identified. Risks range from those low enough that the business can accept them without adverse impact to risks that are so severe they must be avoided at all costs.
To know the difference, practitioners must understand the organization's tolerance for risk -- i.e., how willing it is to take on risk considering the potential outcomes.
Assess each risk against the risk tolerance. For those considered unacceptable, decide how to dispense with them. Many risk management guides talk about four options:
- Avoidance. Put the organization out of harm's way entirely -- e.g., ceasing the business process that a given risk impacts.
- Mitigation. Put a control or countermeasure in place to reduce the likelihood of an outcome.
- Transfer. Use a mechanism -- e.g., insurance -- to shift risk dynamics to another.
- Acceptance. Decide to live with the risk as-is.
Document each decision and the reasons that led to it. Repeat the process for each threat scenario to appropriately apply resources to the risks identified to have the most significant effect on the business.
Once implemented, test to ensure any new security controls perform as intended.
Remember, risk-based security is not a one-and-done exercise; practitioners should establish a cadence of validation over time. Risk profiles change constantly -- the business will adapt how it does things, technologies will change, and threats will evolve. Practitioners should periodically revalidate everything they previously assessed. This is why detailed records of decisions made are so important.
More on risk-based security
Learn how to perform a risk assessment.
Read up on remote work cybersecurity risks and how to prevent them.
Get tips on creating a better vulnerability management program.
Tips for first-timers implementing risk-based security
Getting appropriate support is paramount. In some cases, executive support might suffice, others might require board-level approval. Try to build a risk-aware culture where management buys in and helps practitioners propagate it throughout the organization.
Stakeholder input is essential. Each risk-based security step shows how critical business impact is, but bear in mind that knowledge sharing cuts both ways, so plug business team members into the efforts. Risk mitigation decisions can have a serious effect on operations, which security teams might not fully understand. A risk-based culture pays dividends because business teams can communicate risk information proactively rather than having to be asked.
Achieving total security in an organization is impossible, and budgets aren't unlimited. It's important to deploy resources and expertise intelligently and cost-effectively. A good way to do this is to move to a risk-aware model. While requiring some additional elbow grease to implement, these steps can help move organizations in that direction.
Ed Moyle is a technical writer with more than 25 years of experience in information security. He is a partner at SecurityCurve, a consulting, research and education company.
Michael Cobb contributed to this article.







