information lifecycle management (ILM)

What is information lifecycle management (ILM)?
Information lifecycle management (ILM) is a comprehensive approach to managing an organization's data and associated metadata, starting with its creation and acquisition through when it becomes obsolete and is deleted. An effective ILM strategy can help lower storage and data management costs, as well as reduce the security, compliance and legal risks that come with failing to maintain full control over organizational data.
Unlike earlier approaches to data storage management, ILM deals with all aspects of data throughout its life span, rather than focusing only on one facet of data management. For example, hierarchical storage management is concerned only with automating storage processes and not with how data is transformed or used. ILM addresses how data is utilized and many other issues. In addition, ILM enables more complex criteria for storage management than systems that rely only on basic metrics, such as data age or access frequency.
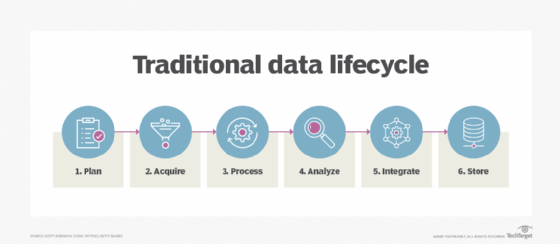
How information lifecycle management works
Information lifecycle management takes a policy-based approach to handling data, providing a centralized, consistent strategy for managing the entire data lifecycle. ILM also facilitates automation and storage tiering. In this way, data can be automatically migrated from one storage tier or format to another based on the applicable policies. As a rule, newer data and data that must be accessed more frequently are stored on faster, more expensive storage media, while less-critical data is stored on slower and cheaper media.
The ILM approach enables IT teams to specify different policies for different types of data throughout its life span. ILM takes into account that data declines in value at different rates, with some types of data retaining its value much longer than other types. In some cases, ILM might also incorporate path management capabilities, which make it easier to retrieve stored data by tracking where it is in the storage cycle.
To be effective, however, ILM needs to be an organization-wide effort, involving procedures and practices, as well as applications and technology platforms. That ability to better track and retrieve information provides a key benefit for IT, the legal team and the business when faced with e-discovery requests, according to consultancy Deloitte.
Deloitte also noted that ILM can introduce "management rigor and controls" of information for the entire business.
Information lifecycle management vs. data lifecycle management
ILM is commonly confused with data lifecycle management (DLM). In fact, the two terms are often used interchangeably; however, they're not the same thing. One way to look at ILM is as a more complex subset of DLM.
So, while DLM products deal with general attributes of files, such as their type, size and age, ILM provides more complex capabilities.
Think of DLM as being concerned with data sets as a whole. However, ILM focuses on what's inside those data sets, such as the information in document files. For example, a DLM product would enable a user to search for a certain file type of a certain age, but an ILM product would enable the user to search through multiple file types for instances of a specific piece of information, such as a customer number and, subsequently, the data associated with that customer account.
The type of control that ILM can provide has become increasingly important as more regulations have been enacted. The European Union's General Data Protection Regulation (GDPR), for example, guarantees an individual's right to be forgotten, and the California Consumer Privacy Act specifies that an individual has the right to know about the personal information that a business collects and how that information is used and shared. An ILM product can help locate the individual's personal data, but a DLM product cannot.
What are the phases of the information lifecycle?
The ILM process is often described in terms of the phases, or stages, that data passes through as part of the information lifecycle. Different resources often define these phases in different ways, although many of them are usually close in concept. The following seven phases provide a general overview of what happens with data during its lifecycle:
- Capture data. Organizations continuously create data and collect data from external sources. That data might be generated manually or automatically. Data sources can include social media, industrial internet of things (IoT), corporate collateral, user-generated content, customer input, sales records or a wide range of other sources.
- Store data. Organizations that create and collect data must find ways to effectively store that data. They might store the data in file, block or object storage systems. They might use different types of storage media and configurations, such as network-attached storage or storage area networks. They might store their data on premises, in the cloud or a combination of both.
- Manage data. It's not enough to simply store data. Organizations must also be able to effectively manage that data. They must ensure the data's security, availability and compliance with corporate, industry and government regulations. They might also classify the data, compress or deduplicate the data, or implement a system for monitoring their data and storage systems.
- Transform data. Few organizations simply capture and store data without transforming it in various ways to make it easier to access and understand. As part of this process, they might cleanse, filter, aggregate, enrich, merge or, in some other way, modify the data to meet their business needs.
- Use data. The purpose of capturing, storing and transforming data is to ensure that users and applications have the data they need to conduct business and carry out their assigned tasks. During this phase, users might view, modify, share or collaborate on data. They might also analyze data or use it to generate reports.
- Archive data. Once data is no longer needed on a daily basis, it is often archived in case it's required for future business needs or to meet regulatory or legal requirements. Organizations typically use slower and cheaper storage systems because data access requirements are minimal. Although archiving data can be an important phase in the ILM process, not all data needs to be archived. For example, data collected by IoT devices might need to be retained only if anomalies have been discovered or only until it has been aggregated and analyzed.
- Destroy data. When an organization is certain that the data is no longer needed and it's not subject to regulatory or legal requirements, it is considered to be at the end of its useful life and can be deleted. The destruction phase is an important step in the ILM process because it reduces the amount of data that has to be stored and the organization's potential liability. All data maintenance and storage come with overhead and costs, even if the data is not needed, so the sooner that data can be safely deleted, the better. In addition, if data is not deleted in a timely manner, it can make it more difficult to work with the current data and make informed business decisions based on that fresh data.
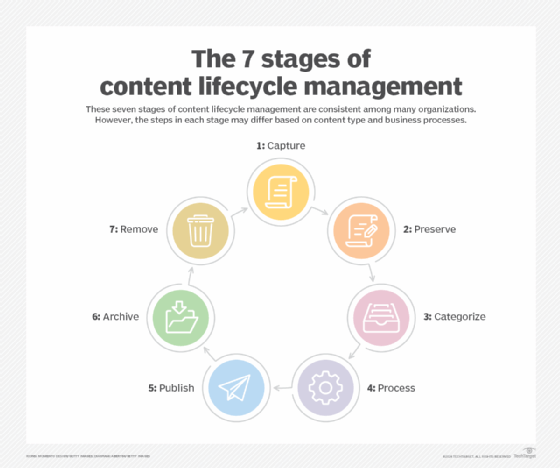
Although data typically passes through all seven stages, this process should not be thought of as a strictly linear flow of information. For example, data creation and collection are ongoing operations that can occur as some of the data passes through other phases. In addition, data might be transformed before it is stored, after it is stored or both before and after. Meanwhile, data use might come right after data is stored, right after it's transformed or both. Data might even be used after it has been archived.
The only phase that consistently follows a linear pattern is the last phase, in which data is deleted.
See best practices to ensure GDPR compliance and business benefits of data protection and GDPR compliance. Explore storage tiering strategies for modern media and why storage tiering is necessary now more than ever. Also, check out benefits of enterprise content management, ways to manage your data storage strategy and how classification of data can solve your data storage problems.






