Data startups at MIT Sloan CIO event aim to fill tech gaps
Cleanlab, The Modern Data Company and Pyte seek to address data quality issues, metadata management and the perils of multiparty data collaboration, respectively.
Data is the critical, if often neglected, ingredient for the expected wave of generative AI projects moving from pilot to production -- not to mention the multitude of traditional AI, machine learning and analytics initiatives.
So, it's hardly surprising that several of the early-stage companies selected as finalists for the 2024 MIT Sloan CIO Symposium's Innovation Showcase focus on aspects of data management and governance. This year's roster includes Cleanlab, which specializes in data quality and data curation for AI and ML uses; The Modern Data Company, which offers a platform for creating data products; and Pyte, which focuses on secure data collaboration with external partners.
The data startups will present their products at the 21st annual event, which runs May 13-14 in Cambridge, Mass. The Innovation Showcase features 10 early-stage companies that sell products to CIOs and IT departments. Participants span technology categories including AI, application modernization, cyber-risk management and customer service analytics, in addition to the data-related ones.
Addressing data quality
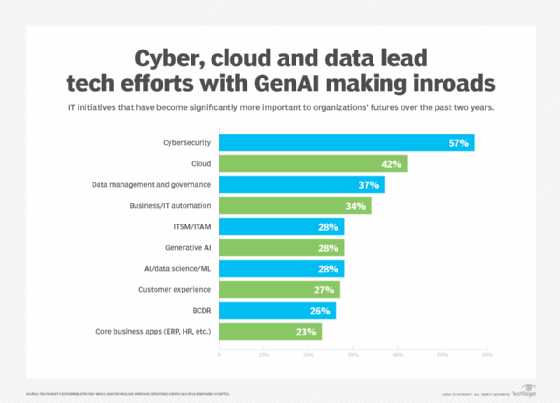
The data thread running through this year's startup roster lines up with IT purchasing trends. Data management and governance ranked third on the list of enterprise technology initiatives that have become significantly more important to organizations over the past two years, according to a February 2024 report from TechTarget's Enterprise Strategy Group. Only cybersecurity and cloud ranked higher in the market research division's "2024 Technology Spending Intentions Survey," which polled 938 business and technology leaders.
Data management and governance ranks third on the list of IT spending priorities.
But data aspirations don't aways translate into results. Indeed, many organizations struggle to create a data culture that makes data readily available for analysis, decision-making or model-building. That's the disconnect the three startups in the Innovation Showcase aim to address.
"If you try to do things with data, as everybody is doing these days, and you're working with low-quality data, as is often the case with any real-world data set, your downstream application is going to be affected," said Anish Athalye, CTO at Cleanlab, based in San Francisco. "If you try to train a machine learning model on low-quality data, you suffer from this 'garbage in, garbage out' problem."
If you try to train a machine learning model on low-quality data, you suffer from this 'garbage in, garbage out' problem.
Anish AthalyeCTO, Cleanlab
The traditional way to boost data quality for building models was to employ a group of data scientists using ad hoc techniques, Athalye noted. Cleanlab's data curation tool, however, takes a systematic, algorithmic approach to finding data issues such as outliers and ambiguous data. The result is a more scalable and reliable way to curate data, he said.
Customers use the technology on the data input side of ML. An IT team within Comcast, for example, uses Cleanlab's product to train ML models on curated data. The team wanted to use ML to identify mistagged IT support tickets -- a Priority 3 ticket categorized as a Priority 1, for instance.
Such applications, while geared to ML, can prove difficult to implement without good data.
"It's a sensible thing to do," Athalye said. "But if you have a low-quality data set to begin with, that's a hard thing to do."
Cleanlab also targets data quality issues from the output perspective. Here, the tendency of a large language model (LLM) used in generative AI applications to hallucinate is a key concern, Athalye said. The company in April launched a Trustworthy Language Model offering that wraps around an LLM and provides a trustworthiness score for every response to a prompt, he added.
Building data products
LLMs also challenge the conventional enterprise data stack, according to Srujan Akula, co-founder and CEO at The Modern Data Company, based in Palo Alto, Calif. The typical centralized data storage layer isn't cutting it when it comes to generative AI, he asserted.
"It's not suitable for these new sorts of use cases where you need to think about data more as a product, rather than as a table or a blob," Akula said.
Treating data as a product looks at it from the business user's point of view: What do they need to do with data and how do they want to consume it? The goal is to make data easier to discover and use. Akula's view of data products, however, also incorporates semantics. Modern's DataOS platform lets organizations build data products that include metadata, which puts data in context and gives it meaning, he noted.
"Managing your metadata better, especially as you're thinking about GenAI and LLMs, is going to be critical," Akula said. "The more context you bring to the data, the higher the accuracy of the models."
The company also plans to take on the task of making LLMs work better with structured data. Generative AI currently works well with unstructured data such as text and images, as opposed to structured data housed in spreadsheets and databases.
"We all understand that GenAI has limitations when it comes to structured data," said Saurabh Gupta, Modern's chief strategy and revenue officer. "What we are trying to address is how we can enable GenAI capabilities on structured data, using methodical approaches, which can be replicated and used across industries."
Securing data collaboration
A business might need to tap an external data provider when building a bigger data set or augmenting customer data with demographic details. But data sharing raises security and privacy concerns.
One approach for bolstering security is a data clean room, in which a third-party company provides an independent environment where enterprises can collaborate. But this approach has its own shortcomings, according to Sadegh Riazi, co-founder and CEO of Pyte, based in Los Angeles.
"Data is disclosed to yet another company and ... you kind of have no oversight over what's happening to your data," he said. "You're trusting the brand and the company to manage it well."
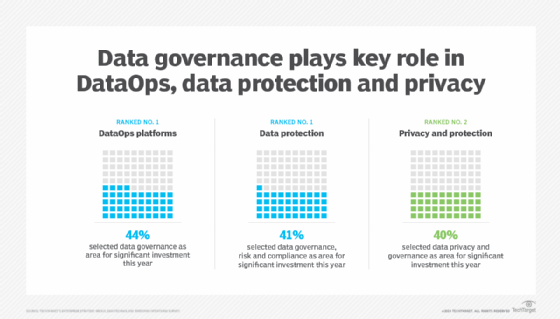
Data management and governance are top considerations in data protection and privacy.
Pyte, a portmanteau of private and byte, takes a different approach. Enterprises install Pyte's encryption software to collaborate instead of onboarding their data to a third party. Their data remains encrypted in transit, at rest and during computation, according to the company.
"All sides can deploy [the] software, they encrypt their data, and they collaborate directly over the encrypted data without ever decrypting it," Riazi said.
The company's data collaboration technology has relevance for CIOs, chief data officers and data platform leaders, he said. CIOs, for example, can use the software to secure data and make it more widely available for business use.
"These two [goals] are usually in contradiction with each other," Riazi said. "[CIOs] can usually satisfy one at the expense of the other. We are essentially making their life easier, allowing the business units to do their job while [the CIOs are] doing their own job correctly, which is securing data."
John Moore is a writer for TechTarget Editorial covering the CIO role, economic trends and the IT services industry.
Dig Deeper on IT applications, infrastructure and operations