Time to rethink cloud architecture for enterprise AI
Enterprise AI systems demand cloud architectures that emphasize persistent state, governance and adaptive infrastructure to ensure long-term reliability.
Enterprises have spent more than a decade refining cloud architectures designed around a clear operational assumption: Applications behave as workloads. Stateless services, containerized APIs and transactional systems scale predictably within infrastructure designed for elasticity, isolation and operational efficiency. However, enterprise AI systems don't behave this way.
Many organizations initially deploy AI models into their existing cloud platforms using familiar patterns, containerized inference services, REST APIs or basic orchestration pipelines. These approaches work well for experimentation. But they rarely hold up under the operational demands of production AI systems.
AI introduces characteristics that reshape infrastructure requirements: persistent contextual state, retrieval pipelines, continuous evaluation loops, model drift and adaptive reasoning behavior. These systems don't simply execute logic; they evolve as their context and training data change. For enterprise technology leaders, the challenge is architectural rather than algorithmic. Long-term reliability, governance and cost control depend less on model choice than on the infrastructure surrounding those models.
Architecting AI specifically for the cloud requires treating AI not as another application workload but as a new category of operational infrastructure.
AI workloads vs. traditional cloud applications
Traditional cloud architectures assume deterministic execution. Applications process requests, execute defined logic and return outputs. Infrastructure observability focuses primarily on system health in areas such as latency, throughput and service availability. AI systems behave differently.
Architecting AI specifically for the cloud requires treating AI not as another application workload but as a new category of operational infrastructure.
Inference pipelines involve multistep reasoning, retrieval from distributed knowledge stores and dynamic routing between mode tools. These processes introduce contextual dependencies that extend beyond the original request. Over time, system behavior evolves as models are retrained, prompts change and retrieval data sets expand.
Three structural characteristics distinguish AI systems from traditional workloads:
Persistent contextual state. Retrieval layers, vector indexes and reasoning traces accumulate operational context that influences future outputs.
Continuous evaluation loops. Production AI platforms must evaluate outputs continuously to detect model drift, hallucination patterns or policy violations.
Expanded governance surfaces. AI systems synthesize information across multiple data domains, increasing the importance of provenance tracking, authorization controls and auditability.
These characteristics shift AI systems from being application components to becoming infrastructure systems that require ongoing operational governance.
Experimentation vs. production
Early enterprise AI initiatives are typically deployed in experimentation environments. These environments emphasize flexibility and speed. Data scientists iterate across models, prompts and evaluation data sets while infrastructure teams provide elastic compute resources. Production AI platforms operate under different constraints.
Once AI begins influencing operational decisions -- customer interactions, financial analysis, clinical support or operational planning -- the infrastructure supporting those systems must satisfy requirements for reliability, governance and traceability. Treating experimentation infrastructure as equivalent to production AI platforms introduces systemic risk.
Evaluation pipelines designed for experimentation can interfere with production inference systems. Model updates introduced for testing can propagate unexpectedly into operational services. A durable architecture separates experimentation environments from production AI platforms through controlled lifecycle pipelines that govern how models, prompts and evaluation artifacts transition into operational systems.
This separation mirrors established software delivery practices but becomes more critical when system behavior itself evolves over time.
Managing state and retrieval infrastructure in hybrid cloud
AI systems also challenge the traditional emphasis on stateless cloud architectures. Modern AI deployments frequently rely on retrieval layers that interact with evolving knowledge repositories and vector indexes. Evaluation frameworks accumulate performance metrics across time. Reasoning pipelines store intermediate context used in multistep decision processes. These components introduce architectural state that must be governed explicitly.
In hybrid and multi-cloud environments, the challenge is more complex. Retrieval pipelines might interact with document repositories, operational databases and domain-specific knowledge systems distributed across different infrastructure environments. Latency requirements, regulatory constraints and data residency rules often dictate where these systems must operate. Therefore, enterprise AI architecture requires deliberate design around how contextual state is stored, synchronized and governed across infrastructure boundaries.
Cost observability and governance
AI platforms change the economics of cloud infrastructure. Traditional workloads scale primarily with traffic patterns. Capacity planning models estimate compute demand based on user activity. AI workloads introduce additional cost drivers.
Inference cost can depend on context length, retrieval depth or dynamic model routing. Training pipelines can generate bursts of high compute demand, and evaluation frameworks can run continuously as part of governance processes. As a result, effective cost governance for AI systems requires behavior-aware observability.
Infrastructure telemetry must capture not only resource consumption but also reasoning behavior, model selection decisions and retrieval activity. Without this visibility, organizations can't reliably explain or control AI infrastructure costs.
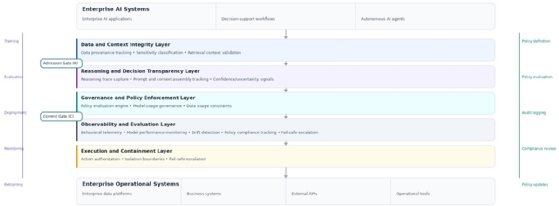
Reference architecture for enterprise AI systems
Operating AI systems reliably in the cloud requires infrastructure designed specifically for adaptive systems. A production AI platform typically consists of five architectural layers:
Data and context integrity layer. Ensures that information entering AI systems carries metadata related to provenance, sensitivity classification and lifecycle constraints.
Reasoning and decision transparency layer. Captures contextual dependencies, decision paths and uncertainty signals that explain system behavior.
Governance and policy enforcement layer. Enforces policies governing data access, model behavior and operational boundaries dynamically during system execution.
Observability and evaluation layer. Provides continuous insight into model performance, policy compliance and behavioral drift.
Execution and containment layer. Controls how AI outputs translate into operational actions through isolation boundaries, rollback mechanisms and escalation paths.
This reference architecture illustrates how enterprise AI platforms enforce data integrity, reasoning transparency, governance policy enforcement, behavioral observability and operational containment across the lifecycle of production AI systems.
The AI platform control stack
Beyond structural layers, production AI platforms require supervisory infrastructure capable of monitoring and influencing behavior across the system. This supervisory capability functions as an AI platform control stack. Rather than embedding governance logic inside application code, the control stack analyzes telemetry from across the AI platform and applies constraints when required.
Key control-stack capabilities typically include policy evaluation, behavioral analysis, lifecycle management, cost governance and runtime intervention.
This architecture separates execution from governance, enabling consistent oversight without embedding complex policy logic inside every AI service.
A control-plane architecture shows how enterprise AI platforms supervise AI execution systems through centralized governance, behavioral evaluation, observability telemetry and runtime policy enforcement.
The AI infrastructure gradient
A pattern frequently emerges as enterprises scale AI deployments. In early stages, AI behaves like a feature embedded within traditional applications. Infrastructure management focuses on deployment pipelines and compute resources. As AI adoption grows, retrieval systems, evaluation loops and reasoning pipelines introduce a persistent operational state. Governance begins shifting toward behavioral monitoring rather than purely infrastructure health.
At mature stages, AI platforms function as supervised infrastructure systems. Dedicated control planes monitor system behavior, enforce policy boundaries and manage lifecycle transitions. This transition can be understood as an AI infrastructure gradient:
Application-embedded AI → Platform-integrated AI → Supervisory AI infrastructure
Understanding this gradient helps explain why many AI initiatives initially appear straightforward but later encounter operational and governance complexity. Organizations that anticipate this shift are better positioned to design infrastructure capable of supporting long-lived AI systems.
What this means for enterprise cloud leaders
Enterprise AI systems operate fundamentally differently from conventional cloud workloads. Their behavior evolves over time, their infrastructure dependencies extend beyond compute layers, and their governance requirements span multiple operational domains. Organizations that treat AI as simply another workload often discover architectural limitations once systems reach scale.
Enterprises that design dedicated lifecycle infrastructure, behavioral observability systems and supervisory control stacks are better positioned to operate AI platforms reliably.
In contrast, enterprises that design dedicated lifecycle infrastructure, behavioral observability systems and supervisory control stacks are better positioned to operate AI platforms reliably. Architecting AI for the cloud isn't primarily about deploying models. It's about designing infrastructure capable of managing intelligent systems as persistent operational components.
The cloud transformed how organizations build software. AI is reshaping how cloud infrastructure itself must be designed.
Varun Raj is a cloud and AI engineering executive with nearly two decades of experience designing large-scale cloud computing and AI platforms. His work focuses on governance architectures that enable generative AI systems to operate safely and reliably in production environments. Raj contributes expert perspectives on cloud platform architecture, AI governance and operational trust through industry publications, technical forums and invited discussions.