Sabre outage puts its 99.995% uptime goal in question
An airline reservation system outage created long lines for travelers and raised questions about whether Sabre's uptime goals are achievable. They may not be.
Sabre Corp.'s outage this week was long enough to delay check-ins and extend airport lines. The airline reservation system outage affected multiple airlines and hubs, but the firm hasn't explained its cause or length.
Last March, Sabre told investors about its annual uptime availability goal of 99.995% for 2019. This is equal to downtime of no more than about 26 minutes a year. But the Sabre outage on Wednesday may have exceeded that.
Sabre's first tweet about the problem came at 11:56 a.m. It said the firm "was aware of the issues" facing customers. About an hour later, at 12:54 p.m., the company tweeted that "systems have recovered."
Based on those tweets alone, the Sabre outage may put the firm closer to four nines of reliability, or 99.99%, rather than five nines, or 99.999%. Four nines means its systems won't face downtime longer than about 53 minutes in a year, but Sabre still has nine months to go.
Sabre declined to comment.
Little triggers often lead to big outages
The cause of the Sabre outage is unknown, but most outages begin small, according to the Uptime Institute.
There's probably some little trigger event that happened that cascaded into this big failure.
Todd Travervice president of IT optimization and strategy, Uptime Institute
"There's probably some little trigger event that happened that cascaded into this big failure," said Todd Traver, vice president of IT optimization and strategy at the Uptime Institute, an advisory group that focuses on improving performance and efficiency for business-critical infrastructure, which includes ERP systems.
Uptime, in a recent report based on an annual survey of its user base, found that almost a third of respondents have experienced an outage or a severe degradation of service. The report concluded "the 99.99% or even 99.999% availability claims made by the industry are out of line with reality." Six-nines reliability means uptime availability for all but 32 seconds a year.
Sabre, in its March report to investors last year, said it is migrating workloads from IBM mainframes to Intel servers. The company expects to complete the migration by 2023. It is hosting its services in public and private clouds.
Sabre, as part of this IT change, described "continuous availability architectures to provide 99.995% uptime and reduced cost vs. traditional [disaster recovery]."
No business is "planning for less than 100%" uptime, Traver said. "They recognize that, in some cases, it will be less, because things happen." Those that suffer big outages "were blindsided by something," he said.
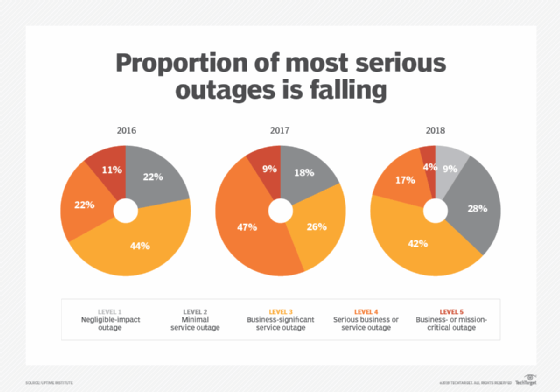
The most serious IT outages, Level 5, are declining thanks to improving management, according to the Uptime Institute.
Causes of system outages
This mission-critical systems advisory group has categorized the causes of downtime and has identified a long list of things that can bring systems down, Traver said. The list includes all manner of network glitches, from fiber cuts to faulty switches, as well as IT problems, configuration mistakes and insufficient testing. Power problems, lightning strikes and things like uninterruptable power supply failures -- such as a circuit breaker issue -- can all contribute, he said.
But Uptime has identified a trend that the proportion of the most serious outages has steadily declined over the last three years.
Uptime ranks outages on five levels, with Level 1 having "negligible" impact and Level 5 being a mission-critical outage, with serious, possibly headline-making ramifications. In 2016, 11% of outages were ranked as a Level 5. In 2018, it was at 4%.
Traver said he believes the decline of the most severe outages is a telling trend. There is more focus today on reliability, and managers "are looking now, more than ever, on the multiple causes of outage," he said.
Another factor is an increasing focus on having mission-critical applications spanning multiple data center sites, so a problem at one site won't create a severe problem, Traver said. Organizations are architecting databases to keep the information in sync across sites. And this means companies "could lose any individual data center, and the application still functions just fine," he said.