Defining requirements key to manage machine learning projects
Machine learning projects are likely to fail without proper planning. 'Managing Machine Learning Projects' provides guidance on how to plan by defining ML project requirements.
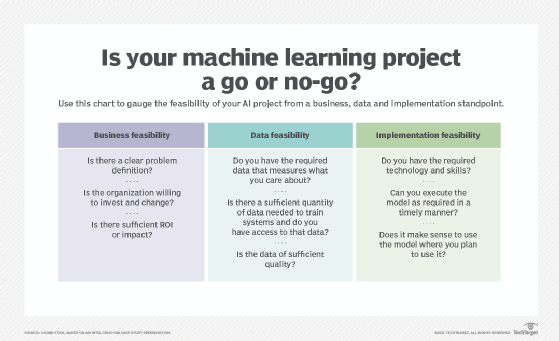
Machine learning projects are likely to fail if they aren't properly planned beforehand. In Chapter 2 of Managing Machine Learning Projects, author Simon Thompson explains the process of defining the requirements an organization typically needs for a successful ML project. Once an organization establishes how it will fund its machine learning endeavor and after making a conscious decision to conduct a structured pre-project investigation to ensure its feasibility, the next step is to look at different requirements.
Thompson outlines three basic types of requirements a development team needs: functional, nonfunctional and system requirements. functional requirements refer to the purpose(s) an ML model serves and what tasks it's expected to do. Nonfunctional requirements mean speed and efficacy, plus the monetary cost and carbon footprint of the planned ML model. System requirements entail the technology infrastructure required to run and maintain the model, as well as what business continuity measures are required in the long run. Thompson then discusses the need to assess the customers and organizations that will, ultimately, use the models, as well as stakeholders and the IT architecture needed. These are referred to as business requirements.
Next, Thompson articulates the need to have at least some sense of what data sets will be used to train the ML models being built. There are, usually, security requirements that limit access to corporate data and data sets because they may contain trade secrets and other intellectual property that can only be released under a strong contractual relationship. Thompson's advice is to acquire samples of such data sets that are representative enough of the breadth of data to be used in the ML project.
 Click here, and get a 35%
Click here, and get a 35%
discount using the code
nltechtarget21.
When using a target organization's data or resources for an ML project, that organization almost certainly has established security protocols to prevent vulnerabilities. These security requirements must be adhered to. Ways to do so include engaging with security experts and assessing data privacy issues. Also, as Thompson makes clear in the section on corporate social responsibility and ethics, while human developers mean well with their projects, they are prone to blind spots and biases. These can be mitigated using structured tools to help them evaluate projects, such as the Algorithmic Impact Assessment tool developed in Canada to determine harm or risks for a given ML project.
In the chapter section "Development Architecture and Process," Thompson discusses the concrete technology systems needed to build such projects, i.e., system requirements. These environments include development environments (dev), testing environments (test) and production environments (prod), but pre-production environments (pre-prod or QA) are often used as well. Thompson advises readers to determine if a customer organization already has an MLOps setup to use for a dev environment and provides a to-do list for when it does not.
Finally, when building prod architecture, it's sufficient at this planning stage to have a basic, high-level overview of what components will be included as part of your deliverable solution. For example, these may include databases; messaging systems to manage the flow of information; execution environments, i.e., where developers' code is executed and all components involved are utilized; dashboarding systems; and authentication systems to manage user accounts.
The remainder of the book walks developers through the typical ML project development process using a series of sprints, or individual chunks of work to be completed. The book adheres to Agile development conventions, and sprints are among the most important of those conventions. Those who complete the book all the way through the final chapter on post-project material will have a vastly better grasp of what it takes to build a successful ML project.
A downloadable PDF version of Chapter 2 is available here.






