The hardware/software vendor diverges from tech giants such as Google, Meta and Microsoft partner OpenAI by making models available to both researchers and for-profit enterprises.
Cerebras is taking on large technology companies and famous startups.
The AI hardware/software vendor on Tuesday released seven open source GPT-trained large language models (LLMs) aimed at both the research community and for-profit enterprises.
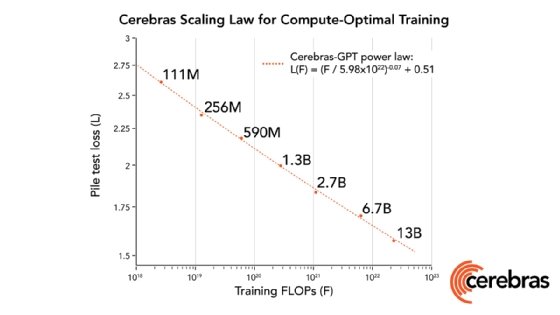
Cerebras' researchers trained the LLMs on 16 CS-2 systems in the Cerebras Andromeda supercluster. The models range in size from 111 million to 13 billion parameters.
Cerebras released all seven models, training methodology and training weights to researchers under the Apache 2.0 license. The models are now available on Cerebras Model Zoo, Hugging Face and GitHub.
A lot of companies used to do a lot of open stuff, and once there was a big pile of money on the table, they stopped doing it.
Karl FreundFounder and analyst, Cambrian AI
"A lot of companies used to do a lot of open stuff, and once there was a big pile of money on the table, they stopped doing it," Cambrian AI founder and analyst Karl Freund said.
For example, Google has been silent on interactive AI chatbot Bard's training data set and parameters because Bard is closed.
"The industry wants this stuff open. By publishing these seven models and making them all open ... I suspect that the engineering community will appreciate that," Freund said.
Meanwhile, some might argue that part of the reason the tech giants have not made their LLMs open source is because of privacy considerations and to mitigate some of the risks, such as misinformation, racism and other problems, that come with training LLMs.
But Cerebras co-founder and CEO Andrew Feldman believes those arguments are contradictory, especially since many vendors also make the LLMs available to the research community.
"The most credible answer is these are strategic assets for their company, and they don't wish to share," Feldman said.
Cerebras is not the first vendor to produce open source LLMs. Bloom is an open source LLM developed by research company Hugging Face and French research agencies Genci and the Institute for Development and Resources in Intensive Scientific Computing, the organizations behind supercomputer Jean Zay.
"The AI community is built on top of each other's work since the beginning," Feldman said. "People don't want it closed. There could be an element of truth of security and safety, but I think it's much more self-serving than that."
While Cerebras' open models won't change the industry immediately, they ought to provide more opportunities to enterprises, said Dylan Patel, an analyst at SemiAnalysis.
"They are showing that it's possible and cheap to train your own models and fine-tune your own models," Patel said. "It does somewhat change the equation of training and inference cost of an enterprise that wants to run and train their own models without being attached to a tech giant."
Cerebras released seven GPT large language models and also introduced its research on the scaling law for compute-optimal training.
Competing with Nvidia GPUs
Cerebras also provides options to enterprises that want to train and run their models without Nvidia's GPUs. The Cerebras CS system is powered by its Wafer-Scale Engine, which the vendor claims is more powerful than GPUs.
Cerebras trained the seven open source models without a big team, the vendor said. Compared with the 35 people needed to train GPT-4, Cerebras said it only needed one person to train all the models.
While it is impressive that Cerebras only required one engineer, Freund said that could change if their models became bigger.
"If you want to go to a trillion parameters, you're going to have to do some of that [comparison] work on CS-2 as well," he said.
This raises the question of how big of a model enterprises need. "There's been a lot of talk in the industry that bigger is not always better," Freund said.
Many now consider that a smaller model could be more affordable and that users can train it with more data.
But Cerebras' success in using one engineer with 16 CS-2s will not necessarily induce more organizations to use the processors, Patel said.
"The biggest challenge is getting people to take this data and immediately start using it on Cerebras hardware rather than just continuing to use existing GPUs," he said.
Moreover, Nvidia's GPUs are popular because they are fast and the ecosystem supports them, Freund said. However, CS-2s could become a significant selling advantage once Cerebras addresses long-term viability concerns.
Cerebras is one of many vendors challenging GPUs, noted Daniel Newman, an analyst at Futurum Research. For example, Groq, another AI hardware/software vendor, recently said it would adapt Meta's Llama model to its chips.
"It's exciting, and I expect more of this type of advancement to challenge the supremacy of the GPU, while also addressing cost and sustainability issues that come from the increased demand for AI," Newman said.
Esther Ajao is a news writer covering artificial intelligence software and systems.