Part of:How to get started with knowledge management
What are the types of knowledge management systems?
In order to understand the different types of knowledge management systems, organizations should know about the different types of knowledge and the history of this market.
Knowledge management is as old as the computer revolution itself. In theory, once information is accessible online, people should be able to ask the computer a question and quickly find the answer. In practice, people struggle to find information when they need it.
Patterns and connections make the difference. Yet, knowledge management may struggle to combine computer technologies with professional best practices, especially as technologies and best practices continuously change. Different types of knowledge management systems, which serve small team or enterprise needs, have different approaches to solve this challenge.
Explore the history of knowledge management and how those events and innovations led to the various types of modern knowledge management systems.
The history of knowledge management
Vannevar Bush, computing pioneer and former MIT professor, envisioned the first knowledge management system -- the memex machine -- in a 1945 article. He also wrote that the human mind operates by associations, rather than formal indexing of information.
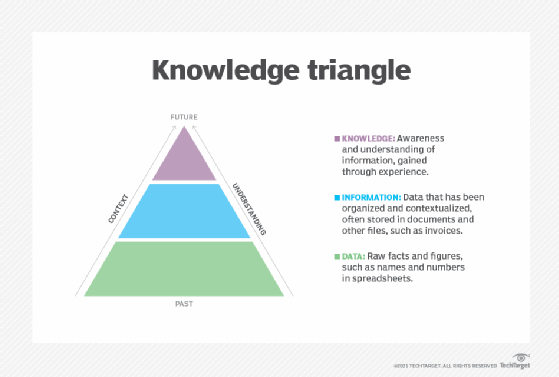
When organized by predefined criteria, data becomes information. Actionable information becomes knowledge.
"With one item in its grasp, [the mind] snaps instantly to the next that is suggested by the association of thoughts, in accordance with some intricate web of trails carried by the cells of the brain … Selection by association, rather than indexing, may yet be mechanized," Bush wrote.
Compared to the human mind, what knowledge do computers understand? Computers are machines that process data. Information and knowledge are higher-order concepts that make data useful. So, knowledge management depends on transforming data into information and information into knowledge.
Specifically, computers process data represented as 0s and 1s. When organized by predefined criteria, data becomes information. Then, actionable information becomes knowledge. For example, 34 is a number, while 34 degrees Fahrenheit is a temperature. If people know this information, they might put on a coat to go outside, while others may decide they dressed warmly enough. This information is actionable, making it knowledge.
This knowledge triangle details the process that data goes through to become knowledge.
Types of knowledge
To make information knowable, organizations must recognize the differences between three types of knowledge:
Explicit knowledge represents information known from the data provided. For example, 34 degrees Fahrenheit is 2 degrees above water's freezing point. This fact can be explicitly tagged as temperature.
Implicit knowledge requires inferencing about the information itself. For example, most people in New England would consider 34 degrees Fahrenheit cold. The temperature is associated with a weather-related category: cold.
Beyond inferencing, tacit knowledge adds insights that people can know if they understand external factors. For example, when the weather is 34 degrees Fahrenheit, parents in New England usually tell their children to put on a coat, hat and gloves before going outside to play or else they may feel cold. Parents have tacit knowledge about how to dress for cold weather.
Knowledge encompasses learning, memory and understanding. In the above example, New England parents have a repository of commonsense knowledge, gained through life experiences with cold weather.
Similarly, organizations capture people's expertise and experiences. Within an enterprise, groups ranging from small teams to entire departments collect information from their digital work. One or more repositories can store and maintain these artifacts, often called information elements.
Repositories differ by purpose and function. Examples include the following:
Repositories use an evolving array of technologies to store, secure and organize different types of content. They assign metadata to identify information elements. As repositories catalog information elements, tag content with appropriate metadata and make this knowledge actionable, they offer the foundations for knowledge management systems.
Types of knowledge management systems
A knowledge management system creates connections between stored information and actionable knowledge. These systems help knowledge workers find information they need, regardless of the specific repository where it resides.
Organizations have multiple approaches to find or develop a knowledge management system. Each approach depends on the computational scale required to store, secure, organize and access information elements.
Organizations should know the differences between systems designed for the following actions:
team activities, where information is participatory and temporary and where the repository serves as a system of engagement; and
enterprise-scale activities, where information is authoritative and long-lasting and where the repository serves as a system of record.
Team activities begin with best practices and standard operating procedures that knowledge workers learn through work. Enterprise-scale operations, by comparison, require formally defined specifications often defined through an information architecture.
This table highlights the distinctions between the different types of knowledge management systems, based on how they handle various types of knowledge.
Types of knowledge
Technologies and best practices based on scale
Team
Enterprise
Explicit
Naming conventions
File plans
Hashtags
Controlled vocabularies
Taxonomies
Implicit
Folksonomies
Conversational channeling
Ontologies
Knowledge graphs
Tacit
Ad hoc sharing
Organizational memory
Expertise locators
Social graphs
Customer data platforms
Organizations should consider how technologies and best practices affect different types of knowledge.
For explicit knowledge, some examples are the following:
Through on-the-job training, team members learn how to name files, identify where to store them within a network file system and invent tags to capture ad hoc categories.
For enterprise-scale activities, workers rely on lists of predefined terms to store, categorize and organize information. These terms are determined through one or more controlled taxonomies specified by an information architecture.
Implicit and tacit knowledge share similar distinctions. Team activities are readily supported through best practices. Enterprise activities depend on investments in innovative computer technologies.
How to design for knowledge management
To develop a knowledge management roadmap, business leaders should pursue strategic investments in repositories and related information technologies. They should also capitalize on investments in professional best practices.
Knowledge workers should pay attention to information flows and the terms used to describe how work gets done. Whether formally defined or part of the organizational culture, these descriptors and categories form the basis for information architectures.
Finally, organizations should recognize that implementing a knowledge management system is an iterative process. The process includes the following steps:
Choose a system. Even a paper-based filing system that relies on ad hoc terminology can be the beginning of a digital filing plan.
Conduct a content audit of valuable business documents, and review the steps in business processes to determine important content types and metadata.
Use existing repositories wherever possible, and extend them as needed with cloud-powered services.
Identify roadblocks and barriers to success, and develop plans to resolve them.
In many cases, incremental improvements to computer technologies or professional best practices can affect how organizations transform stored information into actionable knowledge.