
Getty Images/iStockphoto
A short guide to managing generative AI hallucinations
Generative AI hallucinations cause major problems in the enterprise. Mitigation strategies like retrieval-augmented generation, data validation and continuous monitoring can help.

Generative AI systems occasionally produce false or misleading information, a phenomenon known as hallucination. This issue is becoming more significant as enterprises increasingly rely on AI for their information and data-rich applications.
AI hallucinations can range from annoying inaccuracies to severe business disruptions. When AI systems output false information, it can erode an organization's integrity and result in costly and time-consuming repairs.
To reduce the risk of AI-generated misinformation and enhance system reliability, AI practitioners must understand, identify and mitigate potential hallucination concerns.
What are generative AI hallucinations?
Generative AI hallucinations occur when the AI model produces incorrect, misleading or wholly fabricated information. This phenomenon can arise across various generative AI systems, including text generators, image creators and more.
Hallucinations are typically unintended, stemming from generative AI's reliance on patterns learned from its training data rather than access to external factual databases or real-time information. This reliance can lead to outputs that, while superficially plausible or coherent, are not anchored in reality. Addressing these hallucinations is a significant challenge in AI development.
A typical generative AI hallucination contains fabricated facts, such as incorrect historical events or fictional scientific data. For example, when creating a custom GPT to generate instructions for a software feature, a hallucination might occur if the model produces command-line instructions that do not work when run.
In text-based models like large language models, hallucinations can manifest as factually inaccurate content, false attributions and nonexistent quotes. In image-generating AI, hallucinations involve the creation of images with distorted or unrealistic elements.
Strategies to mitigate AI hallucinations
Mitigating hallucinations can improve the reliability and accuracy of generative AI models. In addition to exploring emerging hallucination mitigation tools, such as Vian AI's Hila platform and the AI Fairness 360 open source toolkit, organizations can implement a number of strategies to help prevent AI hallucinations.
Retrieval-augmented generation
Retrieval-augmented generation (RAG) is a powerful technique in natural language processing. It enhances a generative AI model's performance when presented with a query or task by incorporating a retrieval component.
In RAG, the model retrieves relevant information from an extensive database constructed from various sources, such as corporate content, policies and documentation. This process informs the model's response, providing it with context and specific information directly related to the query. The AI model can then generate a response based not only on its pretrained knowledge and the input query, but also on the information it retrieved.
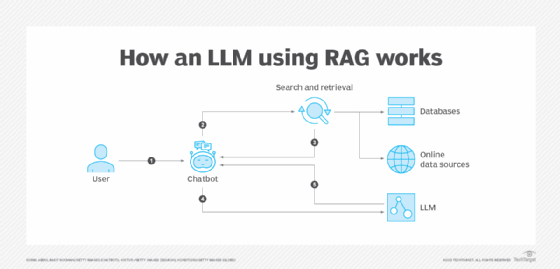
By design, RAG models anchor their responses in actual data rather than relying solely on learned patterns or potentially biased training data. This contextual grounding retrieves real-time or relevant preexisting data before generating a response, thus helping to prevent the model from hallucinating or generating false information.
The output is typically more accurate because responses from RAG models use credible sources or otherwise vetted information. Organizations building AI applications for fields where accuracy is paramount, like medicine, law or science, should consider making RAG a project requirement.
RAG is adaptable to new information over time; organizations only need to update the retrieval database, not the entire RAG model. This adaptability also makes RAG easy to integrate into existing publishing processes.
Rigorous data validation and cleaning
Rigorous data validation and data cleaning are critical steps in AI model development and maintenance, particularly in preventing AI hallucinations.
Validation and cleaning ensure that the data fed into an AI model is accurate and relevant. This process includes steps such as the following:
- Standardizing data formats.
- Removing or correcting inaccurate or corrupt data points.
- Handling missing values appropriately.
Ensuring data quality must be an ongoing process, as poor-quality data is often the culprit behind unreliable or misleading outputs.
Bias in training data is another factor behind AI hallucinations. Biased data about race, political affiliation, gender, socioeconomic status and other factors can skew AI systems to create false and misleading outputs that further harm underserved communities. This is especially concerning given AI's use in impactful areas like hiring, law enforcement and financial transactions such as loan approvals.
Continuous monitoring and testing of AI output
To continuously monitor and test AI output, implement automated frameworks for unit and integration testing in DevOps pipelines. Then, augment automated testing with human-in-the-loop testing, where human reviewers provide feedback, identify errors and recommend data retraining practices to increase accuracy.
Iterative feedback loops
Whether launching a new custom GPT to solve a business problem or a fully cloud-native AI application, having a feedback loop is crucial.
In the case of a custom GPT, it's simple enough to direct users to send feedback via a team Slack channel or other group chat. It's also beneficial to have a GPT owner on the team to address user questions.
Full-scale AI applications benefit from the same observability and monitoring practices that should already be in place, including the following:
- Distributed tracing to track requests across microservices.
- Comprehensive logging and monitoring to log critical metrics and monitor the health and performance of AI applications.
- Monitoring model performance, including tracking accuracy and performance metrics of AI models in production, and using model drift detection alerts to ensure accuracy over time.
Will Kelly is a freelance writer and content strategist who has written about cloud, DevOps, AI and enterprise mobility.







