BERT language model
What is BERT?
BERT language model is an open source machine learning framework for natural language processing (NLP). BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context. The BERT framework was pretrained using text from Wikipedia and can be fine-tuned with question-and-answer data sets.
BERT, which stands for Bidirectional Encoder Representations from Transformers, is based on transformers, a deep learning model in which every output element is connected to every input element, and the weightings between them are dynamically calculated based upon their connection.
Historically, language models could only read input text sequentially -- either left-to-right or right-to-left -- but couldn't do both at the same time. BERT is different because it's designed to read in both directions at once. The introduction of transformer models enabled this capability, which is known as bidirectionality. Using bidirectionality, BERT is pretrained on two different but related NLP tasks: masked language modeling (MLM) and next sentence prediction (NSP).
The objective of MLM training is to hide a word in a sentence and then have the program predict what word has been hidden based on the hidden word's context. The objective of NSP training is to have the program predict whether two given sentences have a logical, sequential connection or whether their relationship is simply random.
Background and history of BERT
Google first introduced the transformer model in 2017. At that time, language models primarily used recurrent neural networks (RNN) and convolutional neural networks (CNN) to handle NLP tasks.
CNNs and RNNs are competent models, however, they require sequences of data to be processed in a fixed order. Transformer models are considered a significant improvement because they don't require data sequences to be processed in any fixed order.
Because transformers can process data in any order, they enable training on larger amounts of data than was possible before their existence. This facilitated the creation of pretrained models like BERT, which was trained on massive amounts of language data prior to its release.
In 2018, Google introduced and open sourced BERT. In its research stages, the framework achieved state-of-the-art results in 11 natural language understanding (NLU) tasks, including sentiment analysis, semantic role labeling, text classification and the disambiguation of words with multiple meanings. Researchers at Google AI Language published a report that same year explaining these results.
Completing these tasks distinguished BERT from previous language models, such as word2vec and GloVe. Those models were limited when interpreting context and polysemous words, or words with multiple meanings. BERT effectively addresses ambiguity, which is the greatest challenge to NLU, according to research scientists in the field. It's capable of parsing language with a relatively human-like common sense.
In October 2019, Google announced that it would begin applying BERT to its U.S.-based production search algorithms.
It is estimated that BERT enhances Google's understanding of approximately 10% of U.S.-based English language Google search queries. Google recommends that organizations not try to optimize content for BERT, as BERT aims to provide a natural-feeling search experience. Users are advised to keep queries and content focused on the natural subject matter and natural user experience.
BY December 2019, BERT had been applied to more than 70 different languages. The model has had a large impact on voice search as well as text-based search, which prior to 2018 had been error-prone with Google's NLP techniques. Once BERT was applied to many languages, it improved search engine optimization; its proficiency in understanding context helps it interpret patterns that different languages share without having to completely understand the language.
BERT went on to influence many artificial intelligence systems. Various lighter versions of BERT and similar training methods have been applied to models from GPT-2 to ChatGPT.
How BERT works
The goal of any given NLP technique is to understand human language as it is spoken naturally. In BERT's case, this means predicting a word in a blank. To do this, models typically train using a large repository of specialized, labeled training data. This process involves linguists doing laborious manual data labeling.
BERT, however, was pretrained using only a collection of unlabeled, plain text, namely the entirety of English Wikipedia and the Brown Corpus. It continues to learn through unsupervised learning from unlabeled text and improves even as it's being used in practical applications such as Google search.
BERT's pretraining serves as a base layer of knowledge from which it can build its responses. From there, BERT can adapt to the ever-growing body of searchable content and queries, and it can be fine-tuned to a user's specifications. This process is known as transfer learning. Aside from this pretraining process, BERT has multiple other aspects it relies on to function as intended, including the following:
Transformers
Google's work on transformers made BERT possible. The transformer is the part of the model that gives BERT its increased capacity for understanding context and ambiguity in language. The transformer processes any given word in relation to all other words in a sentence, rather than processing them one at a time. By looking at all surrounding words, the transformer enables BERT to understand the full context of the word and therefore better understand searcher intent.
This is contrasted against the traditional method of language processing, known as word embedding. This approach was used in models such as GloVe and word2vec. It would map every single word to a vector, which represented only one dimension of that word's meaning.
Masked language modeling
Word embedding models require large data sets of structured data. While they are adept at many general NLP tasks, they fail at the context-heavy, predictive nature of question answering because all words are in some sense fixed to a vector or meaning.
BERT uses an MLM method to keep the word in focus from seeing itself, or having a fixed meaning independent of its context. BERT is forced to identify the masked word based on context alone. In BERT, words are defined by their surroundings, not by a prefixed identity.
Self-attention mechanisms
BERT also relies on a self-attention mechanism that captures and understands relationships among words in a sentence. The bidirectional transformers at the center of BERT's design make this possible. This is significant because often, a word may change meaning as a sentence develops. Each word added augments the overall meaning of the word the NLP algorithm is focusing on. The more words that are present in each sentence or phrase, the more ambiguous the word in focus becomes. BERT accounts for the augmented meaning by reading bidirectionally, accounting for the effect of all other words in a sentence on the focus word and eliminating the left-to-right momentum that biases words towards a certain meaning as a sentence progresses.
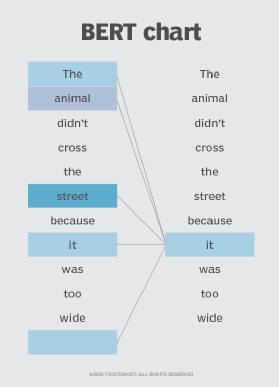
For example, in the image above, BERT is determining which prior word in the sentence the word "it" refers to, and then using the self-attention mechanism to weigh the options. The word with the highest calculated score is deemed the correct association. In this example, "it" refers to "animal", not "street". If this phrase was a search query, the results would reflect this subtler, more precise understanding BERT reached.
Next sentence prediction
NSP is a training technique that teaches BERT to predict whether a certain sentence follows a previous sentence to test its knowledge of relationships between sentences. Specifically, BERT is given both sentence pairs that are correctly paired and pairs that are wrongly paired so it gets better at understanding the difference. Over time, BERT gets better at predicting next sentences accurately. Typically, both NSP and MLM techniques are used simultaneously.
What is BERT used for?
Google uses BERT to optimize the interpretation of user search queries. BERT excels at functions that make this possible, including the following:
- Sequence-to-sequence language generation tasks such as:
-
- Question answering.
- Abstract summarization.
- Sentence prediction.
- Conversational response generation.
- NLU tasks such as:
-
- Polysemy and coreference resolution. Coreference means words that sound or look the same but have different meanings.
- Word sense disambiguation.
- Natural language inference.
- Sentiment classification.
BERT is open source, meaning anyone can use it. Google claims that users can train a state-of-the-art question-and-answer system in just 30 minutes on a cloud tensor processing unit, and in a few hours using a graphic processing unit. Many other organizations, research groups and separate factions of Google are fine-tuning the model's architecture with supervised training to either optimize it for efficiency or specialize it for specific tasks by pretraining BERT with certain contextual representations. Examples include the following:
- PatentBERT. This BERT model is fine-tuned to perform patent classification tasks.
- DocBERT. This model is fine-tuned for document classification tasks.
- BioBERT. This biomedical language representation model is for biomedical text mining.
- VideoBERT. This joint visual-linguistic model is used in unsupervised learning of unlabeled data on YouTube.
- SciBERT. This model is for scientific text.
- G-BERT. This pretrained BERT model uses medical codes with hierarchical representations through graph neural networks and then fine-tuned for making medical recommendations.
- TinyBERT by Huawei. This smaller, "student" BERT learns from the original "teacher" BERT, performing transformer distillation to improve efficiency. TinyBERT produced promising results in comparison to BERT-base while being 7.5 times smaller and 9.4 times faster at inference.
- DistilBERT by Hugging Face. This smaller, faster and cheaper version of BERT is trained from BERT, then certain architectural aspects are removed to improve efficiency.
- ALBERT. This lighter version of BERT lowers memory consumption and increases the speed with which the model is trained.
- SpanBERT. This model improved BERT's ability to predict spans of text.
- RoBERTa. Through more advanced training methods, this model was trained on a bigger data set for a longer time to improve performance.
- ELECTRA. This version has been tailored to generate high-quality representations of text.

BERT vs. generative pre-trained transformers (GPT)
While BERT and GPT models are among the best language models, they exist for different reasons. The initial GPT-3 model, along with OpenAI's subsequent more advanced GPT models, are also language models trained on massive data sets. While they share this in common with BERT, BERT differs in multiple ways.
BERT
Google developed BERT to serve as a bidirectional transformer model that examines words within text by considering both left-to-right and right-to-left contexts. It helps computer systems understand text as opposed to creating text, which GPT models are made to do. BERT excels at NLU tasks as well as performing sentiment analysis. It's ideal for Google searches and customer feedback.
GPT
GPT models differ from BERT in both their objectives and their use cases. GPT models are forms of generative AI that generate original text and other forms of content. They're also well-suited for summarizing long pieces of text and text that's hard to interpret.
BERT and other language models differ not only in scope and applications but also in architecture. Learn more about GPT-3's architecture and how it's different from BERT.







