What are masked language models (MLMs)?

Masked language models (MLMs) are used in natural language processing (NLP) tasks for training language models. Certain words and tokens in a specific input are randomly masked or hidden in this approach and the model is then trained to predict these masked elements by using the context provided by the surrounding words.
Masked language modeling is a type of self-supervised learning in which the model learns to produce text without explicit labels or annotations. Instead, it draws its supervision from the incoming text. Because of this feature, masked language modeling can be used to carry out various NLP tasks such as text classification, answering questions and text generation.
Masked language modeling particularly helps with training transformer models such as Bidirectional Encoder Representations from Transformers (BERT), GPT and RoBERTa.
How do Masked Language Models work?
As a pretraining technique for deep learning models in NLP, MLMs work by masking a portion of the input tokens in a sentence at random and then asking the model to predict the masked tokens. The model is trained on huge volumes of text data so that it can learn to recognize word context and forecast masked tokens depending on their context. For example, in the sentence, "The cat [MASK] the tree," the model would predict the word climbed as the masked token.
This article is part of
What is GenAI? Generative AI explained
Throughout the training process, the model is updated based on the difference between its predictions and the words in the sentence. The pretraining phase assists the model in learning valuable contextual representations of words, which can then be fine-tuned for specific NLP tasks.
The goal of masked language modeling is to use the large amounts of text data available to train a general-purpose language model that can be applied to a variety of NLP challenges.
What is Hugging Face?
Hugging Face is an artificial intelligence (AI) research organization that specializes in creating open source tools and libraries for NLP tasks. Serving as a hub for both AI experts and enthusiasts, it functions similarly to a GitHub for AI. Initially introduced in 2017 as a chatbot app for teenagers, Hugging Face has transformed over the years into a platform where a user can host, train and collaborate on AI models with their teams.
Hugging Face offers various libraries and tools that can be used for masked language projects, including the following:
- Transformers. Transformers are a recent breakthrough in machine learning (ML) and AI models and have been creating a lot of buzz. Hugging Face includes Python libraries with pretrained transformer models and tools for fine-tuning models.
- Tokenizers. Tokenizers are a library for effective preprocessing and tokenization of text. Since models can only handle numerical data, tokenizers are necessary to translate text inputs into numbers. Therefore, the main function of tokenizers is to convert text into data that the MLM can process.
- Data sets. Hugging Face offers an extensive collection of NLP data sets that can be accessed, downloaded and processed.
- Inference application programming interface. These are hosted APIs for pretrained language models that can be used for various NLP tasks.
- Model Hub. Model Hub is a resource for discovering, sharing and deploying transformer models that have already been trained.
Many pretrained deep learning models, such as BERT, GPT-2 and Google's Text-to-Text Tranfer Transformer (T5), are available in their well-known transformers collection, along with resources for optimizing these models for particular workloads. Hugging Face aims to promote NLP research and democratize access to cutting-edge AI technologies and trends.
Masked language modeling in BERT
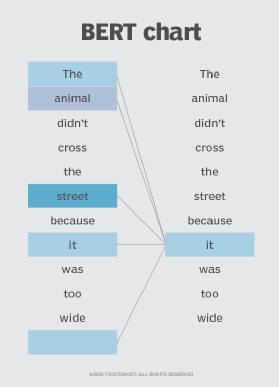
The BERT model is an example of a pretrained MLM that consists of multiple layers of transformer encoders stacked on top of each other. Various large language models, such as BERT, use a fill-in-the-blank approach in which the model uses the context words around a mask token to anticipate what the masked word should be.
BERT is classified into two types -- BERTBASE and BERTLARGE -- based on the number of encoder layers, self-attention heads and hidden vector size. For the masked language modeling task, the BERTBASE architecture used is bidirectional. This means that it considers both the left and right context for each token. Because of this bidirectional context, the model can capture dependencies and interactions between words in a phrase.
This BERT method is ideal for training a language model in a self-supervised situation without human-annotated labels. The model can then be fine-tuned for various supervised NLP tasks.
Benefits of masked language models
MLMs offer several benefits in NLP tasks. Key advantages of MLMs include the following:
- Enhanced contextual understanding. By forecasting masked tokens depending on the surrounding context, MLMs help language models learn contextual information. This makes it possible for the model to represent the connections and dependencies among words in a sequence.
- Bidirectional information. During training, MLMs such as BERT consider the context of a masked token. This bidirectional strategy results in better language understanding, which helps the model derive meaning and context from the words that surround a given word.
- Pretraining for downstream tasks. Masked language modeling works as an effective pretraining technique for different downstream NLP tasks. MLMs can acquire broad language representations that can be optimized for particular tasks such as sentiment analysis, text categorization, named entity recognition and question answering by pretraining on vast amounts of unlabeled data.
- Semantic similarity. MLMs can quantify semantic similarity between sentences or phrases. Through a comparison of the representations of masked tokens in distinct sentences, an MLM can discern the similarity or correlation within the underlying text.
- Transfer learning. MLMs such as BERT showcase strong transfer learning capabilities. The initial pretraining on an extensive corpus lets the model grasp general language understanding, subsequently enabling fine-tuning on smaller labeled data sets that are tailored to specific tasks.
How is MLM different from CLM?
The two main language modeling approaches are masked language modeling and causal language modeling (CLM). The following points highlight the differences between the two models:
- Masked language modeling is a self-supervised learning process that involves training a linguistic model to predict masked tokens in a sequence. While CLM is also a self-supervised learning task, the language model in CLM is trained to predict the next word in a sequence given the previous words.
- In masked language modeling, a certain percentage of tokens in a sequence are randomly masked and the model is trained to estimate the original value of these masked tokens based on the context provided by the other tokens in the sequence. With CLM, the model is trained to produce the subsequent word in a sequence by using the context the preceding words provide.
- Language models such as BERT typically use masked language modeling as their pretraining objective, while CLM is utilized by GPT models such as GPT-2 for their pretraining goal.
- Masked language modeling helps the model learn context and grasp bidirectional relationships between words in a sentence. Since CLM only considers the words that came before it when predicting a word, it concentrates on capturing the unidirectional dependencies in a sequence.
In short, both masked language modeling and CLM are self-supervised learning tasks used in language modeling. Masked language modeling predicts masked tokens in a sequence, enabling the model to capture bidirectional dependencies, while CLM predicts the next word in a sequence, focusing on unidirectional dependencies. Both approaches have been successful in pretraining language models and have been used in various NLP applications.
How is MLM different from Word2Vec?
Similar to masked language modeling and CLM, Word2Vec is an approach used in NLP where the vectors capture the semantics of the words and the relationships between them by using a neural network to learn the vector representations.
However, Word2Vec differs from self-supervised training models such as masked language modeling in the following ways:
- Word2Vec is an unsupervised learning algorithm that's used to generate word embeddings.
- It captures the syntactic and semantic links between words by representing them as dense vectors in a continuous vector space.
- Word2Vec acquires word embeddings by training on large corpora and predicting the context of words within a designated text window, encompassing either the target word itself or the surrounding words.
- It can be trained using two different algorithms -- Continuous Bag of Words and Skip-Gram.
- Word2Vec embeddings are often used to measure word similarity or as input features for downstream natural language processing tasks.
For more on generative AI, read the following articles:
What is a large language model (LLM)?
GANs vs. VAEs: What is the best generative approach?
CNN vs. GAN: How are they different?
Popular masked language models
Examples of MLMs include the following:
- BERT. BERT is the most widely used MLM. It uses a transformer architecture for pretraining substantial volumes of unlabeled text data. This model also performs well on a diverse range of NLP tasks.
- RoBERTa. RoBERTa is an improved version of BERT that enhances pretraining efficiency. It trains on even more data and eliminates some of BERT's training objectives, which improves performance on downstream jobs.
- ALBERT. ALBERT, also known as "A Lite BERT," is a more effective variant of BERT that preserves performance while lowering the size of the model and computing needs. Factorized embedding parameterization and parameter sharing strategies are used to accomplish this.
- GPT. The GPT series is a type of predictive transformer. The GPT series, including GPT-3 and GPT-4 developed by OpenAI, has a transformer-based design and has produced state-of-the-art results in a range of language tasks.
- Google's T5. T5 defines all NLP jobs as text-to-text problems and has demonstrated adaptability to a broad range of activities.
Generative adversarial networks (GANs) dominated the AI landscape until the emergence of transformers. Explore the distinctions between GANs and transformers and consider how the integration of these two techniques might yield enhanced results for users in the future.






