
What is natural language generation (NLG)?
What is natural language generation (NLG)?
Natural language generation (NLG) is the use of artificial intelligence (AI) programming to produce written or spoken narratives from a data set. NLG is related to human-to-machine and machine-to-human interaction, including computational linguistics, natural language processing (NLP) and natural language understanding (NLU).
Research about NLG often focuses on building computer programs that provide data points with context. Sophisticated NLG software can mine large quantities of numerical data, identify patterns and share that information in a way that is easy for humans to understand. The speed of NLG software is especially useful for producing news and other time-sensitive stories on the internet. At its best, NLG output can be published verbatim as web content.
How does NLG work?
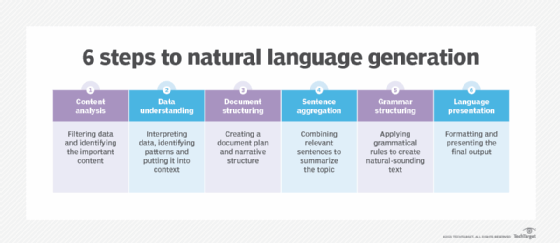
NLG is a multi-stage process, with each step further refining the data being used to produce content with natural-sounding language. The six stages of NLG are as follows:
- Content analysis. Data is filtered to determine what should be included in the content produced at the end of the process. This stage includes identifying the main topics in the source document and the relationships between them.
- Data understanding. The data is interpreted, patterns are identified and it's put into context. Machine learning is often used at this stage.
- Document structuring. A document plan is created and a narrative structure chosen based on the type of data being interpreted.
- Sentence aggregation. Relevant sentences or parts of sentences are combined in ways that accurately summarize the topic.
- Grammatical structuring. Grammatical rules are applied to generate natural-sounding text. The program deduces the syntactical structure of the sentence. It then uses this information to rewrite the sentence in a grammatically correct manner.
- Language presentation. The final output is generated based on a template or format the user or programmer has selected.
How is NLG used?
Natural language generation is being used in an array of ways. Some of the many uses include the following:
- generating the responses of chatbots and voice assistants such as Google's Alexa and Apple's Siri;
- converting financial reports and other types of business data into easily understood content for employees and customers;
- automating lead nurturing email, messaging and chat responses;
- personalizing responses to customer emails and messages;
- generating and personalizing scripts used by customer service representatives;
- aggregating and summarizing news reports;
- reporting on the status of internet of things devices; and
- creating product descriptions for e-commerce webpages and customer messaging.
NLG vs. NLU vs. NLP
NLP is an umbrella term that refers to the use of computers to understand human language in both written and verbal forms. NLP is built on a framework of rules and components, and it converts unstructured data into a structured data format.
This article is part of
What is enterprise AI? A complete guide for businesses
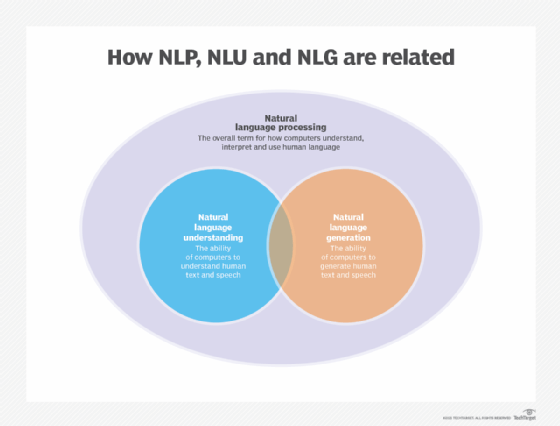
NLP encompasses both NLG and NLU, which have the following distinct, but related capabilities:
- NLU refers to the ability of a computer to use syntactic and semantic analysis to determine the meaning of text or speech.
- NLG enables computing devices to generate text and speech from data input.
Chatbots and "suggested text" features in email clients, such as Gmail's Smart Compose, are examples of applications that use both NLU and NLG. Natural language understanding lets a computer understand the meaning of the user's input, and natural language generation provides the text or speech response in a way the user can understand.
NLG is connected to both NLU and information retrieval. It is also related to text summarization, speech generation and machine translation. Much of the basic research in NLG also overlaps with computational linguistics and the areas concerned with human-to-machine and machine-to-human interaction.
NLG models and methodologies
NLG relies on machine learning algorithms and other approaches to create machine-generated text in response to user inputs. Some of the methodologies used include the following:
Markov chain. The Markov model is a mathematical method used in statistics and machine learning to model and analyze systems that are able to make random choices, such as language generation. Markov chains start with an initial state and then randomly generate subsequent states based on the prior one. The model learns about the current state and the previous state and then calculates the probability of moving to the next state based on the previous two. In a machine learning context, the algorithm creates phrases and sentences by choosing words that are statistically likely to appear together.
Recurrent neural network (RNN). These AI systems are used to process sequential data in different ways. RNNs can be used to transfer information from one system to another, such as translating sentences written in one language to another. RNNs are also used to identify patterns in data which can help in identifying images. An RNN can be trained to recognize different objects in an image or to identify the various parts of speech in a sentence.
Long short-term memory (LSTM). This type of RNN is used in deep learning where a system needs to learn from experience. LSTM networks are commonly used in NLP tasks because they can learn the context required for processing sequences of data. To learn long-term dependencies, LSTM networks use a gating mechanism to limit the number of previous steps that can affect the current step.
Transformer. This neural network architecture is able to learn long-range dependencies in language and can create sentences from the meanings of words. Transformer is related to AI. It was developed by OpenAI, a nonprofit AI research company in San Francisco. Transformer includes two encoders: one for processing inputs of any length and another to output the generated sentences.
The three main Transformer models are as follows:
- Generative Pre-trained Transformer (GPT) is a type of NLG technology used with business intelligence (BI) software. When GPT is implemented with a BI system, it uses NLG technology or machine learning algorithms to write reports, presentations and other content. The system generates content based on information it is fed, which could be a combination of data, metadata and procedural rules.
- Bidirectional Encoder Representations from Transformers (BERT) is the successor to the Transformer system that Google originally created for its speech recognition service. BERT is a language model that learns human language by learning the syntactic information, which is the relationships between words, and the semantic information, which is the meaning of the words.
- XLNet is an artificial neural network that is trained on a set of data. It identifies patterns that it uses to make a logical conclusion. An NLP engine can extract information from a simple natural language query. XLNet aims to teach itself to be able to read and interpret text and use this knowledge to write new text. XLNet has two parts: an encoder and a decoder. The encoder uses the syntactic rules of language to convert sentences into vector-based representation; the decoder uses these rules to convert the vector-based representation back into a meaningful sentence.
Learn more about why NLP is at the forefront of AI adoption and the key role that NLP and NLG are playing in the application of AI in the enterprise.







