
Getty Images
Compare natural language processing vs. machine learning
Both natural language processing and machine learning identify patterns in data. What sets them apart is NLP's language focus vs. ML's broader applicability to many AI processes.

Natural language processing and machine learning are both subtopics in the broader field of AI. Often, the two are talked about in tandem, but they also have crucial differences.
Machine learning (ML) is an integral field that has driven many AI advancements, including key developments in natural language processing (NLP). While there is some overlap between ML and NLP, each field has distinct capabilities, use cases and challenges.
ML uses algorithms to teach computer systems how to perform tasks without being directly programmed to do so, making it essential for many AI applications. NLP, on the other hand, focuses specifically on enabling computer systems to comprehend and generate human language, often relying on ML algorithms during training.
What is machine learning?
ML is a subfield of AI that focuses on training computer systems to make sense of and use data effectively. Computer systems use ML algorithms to learn from historical data sets by finding patterns and relationships in the data. One key characteristic of ML is the ability to help computers improve their performance over time without explicit programming, making it well-suited for task automation.
Although ML has gained popularity recently, especially with the rise of generative AI, the practice has been around for decades. ML is generally considered to date back to 1943, when logician Walter Pitts and neuroscientist Warren McCulloch published the first mathematical model of a neural network. This, alongside other computational advancements, opened the door for modern ML algorithms and techniques.
Types of machine learning
There are four main approaches to training ML models: supervised, unsupervised, semi-supervised and reinforcement learning. Each learning type involves its own set of practices for data collection, data labeling and algorithm training.

Machine learning use cases
ML offers an array of benefits for enterprises. Automating tasks with ML can save companies time and money, and ML models can handle tasks at a scale that would be impossible to manage manually.
There are a variety of strategies and techniques for implementing ML in the enterprise. Developing an ML model tailored to an organization's specific use cases can be complex, requiring close attention, technical expertise and large volumes of detailed data. MLOps -- a discipline that combines ML, DevOps and data engineering -- can help teams efficiently manage the development and deployment of ML models.
Because ML tends to elicit better understanding and use of data, it has a wide range of use cases across industries, from healthcare to financial services to business and retail. Examples of ML use cases include the following:
- Make predictions.
- Generate content.
- Classify and cluster data points.
- Power recommendation engines.
- Assist self-driving cars.
- Aid in medical diagnostics.
- Detect fraud or threats.
- Filter spam.
- Automate organizational processes.
- Supplement other AI and software engineering processes.
What is natural language processing?
NLP is a subfield of AI that involves training computer systems to understand and mimic human language using a range of techniques, including ML algorithms.
By teaching a computer to comprehend natural language, NLP opens the lines of communication between computers and humans and enhances workflow efficiency. NLP helps organizations analyze and gain insights from both structured and unstructured natural-language data, such as emails, documents and articles.
The field of NLP, like many other AI subfields, is commonly viewed as originating in the 1950s. One key development occurred in 1950 when computer scientist and mathematician Alan Turing first conceived the imitation game, later known as the Turing test. This early benchmark test used the ability to interpret and generate natural language in a humanlike way as a measure of machine intelligence -- an emphasis on linguistics that represented a crucial foundation for the field of NLP.
Early iterations of NLP were rule-based, relying on linguistic rules rather than ML algorithms to learn patterns in language. As computers and their underlying hardware advanced, NLP evolved to incorporate more rules and, eventually, algorithms, becoming more integrated with engineering and ML.
The rise of ML in the 2000s saw enhanced NLP capabilities, as well as a shift from rule-based to ML-based approaches. Today, in the era of generative AI, NLP has reached an unprecedented level of public awareness with the popularity of large language models like ChatGPT. NLP's ability to teach computer systems language comprehension makes it ideal for use cases such as chatbots and generative AI models, which process natural-language input and produce natural-language output.
Natural language processing techniques
There are two main techniques in NLP: syntax and semantics.
Syntax-driven techniques involve analyzing the structure of sentences to discern patterns and relationships between words. Examples include parsing, or analyzing grammatical structure; word segmentation, or dividing text into words; sentence breaking, or splitting blocks of text into sentences; and stemming, or removing common suffixes from words.
Semantic techniques focus on understanding the meanings of individual words and sentences. Examples include word sense disambiguation, or determining which meaning of a word is relevant in a given context; named entity recognition, or identifying proper nouns and concepts; and natural language generation, or producing human-like text.
NLP is divided into two main phases. The first phase is data preprocessing, in which data is prepared for analysis. Examples of data preparation techniques include the following:
- Entity extraction, or identifying relevant pieces of information.
- Lemmatization, or reducing words to their base form, known as a lemma.
- Part-of-speech tagging, or identifying words by their grammatical function.
- Stop word removal, or eliminating common and unimportant words, such as and or the.
- Tokenization, or splitting text into shorter units such as words, phrases and syllables, known as tokens.
Once data preprocessing is done, the second stage is algorithm development. This phase involves two main types of algorithms: rule-based and ML.
From the 1950s to the 1990s, NLP primarily used rule-based approaches, where systems learned to identify words and phrases using detailed linguistic rules. As ML gained prominence in the 2000s, ML algorithms were incorporated into NLP, enabling the development of more complex models. For example, the introduction of deep learning led to much more sophisticated NLP systems.
Natural language processing use cases
NLP is employed in many AI systems and tools where computers need to comprehend and utilize natural language. The following are a few examples of real-world NLP use cases:
- Analysis and categorization of textual data.
- Grammar and plagiarism checkers.
- Language generation and translation.
- Sentiment analysis.
- Spam detection.
- Speech and voice recognition.
Natural language processing vs. machine learning
Since the field's shift away from rule-based processing, NLP often uses ML and deep learning techniques to teach computers natural-language comprehension.
ML and deep learning algorithms are well-suited for processing large, complex textual data sets. As a result, ML and deep learning form the basis of many NLP techniques. A common analogy is that ML is to NLP as math is to physics: ML is foundational to NLP processes.
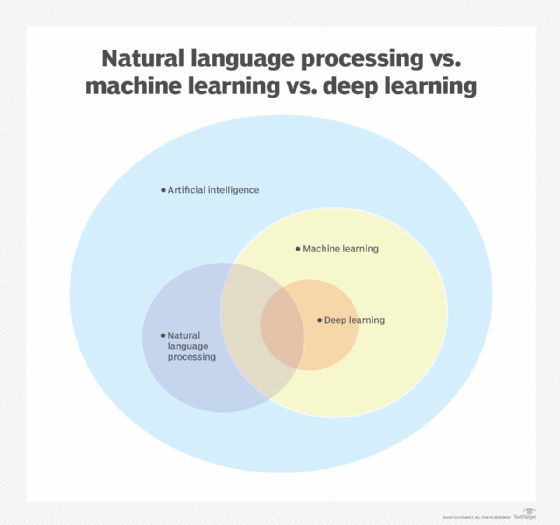
While there is some overlap between NLP and ML -- particularly in how NLP relies on ML algorithms and deep learning -- simpler NLP tasks can be performed without ML. But for organizations handling more complex tasks and interested in achieving the best results with NLP, incorporating ML is often recommended.
Despite their overlap, NLP and ML also have unique characteristics that set them apart, specifically in terms of their applications and challenges.
Applications
Broadly speaking, NLP and ML have different focuses. ML trains computer systems to identify patterns in data generally, whereas NLP's focus is patterns in language specifically. This distinction also makes their applications unique: ML has a wide range of uses, including supporting other AI processes like NLP, while NLP's functions are narrower, centering on language-related tasks.
ML has a wide range of applications, including the following:
- Anomaly detection, which involves identifying outlier entities, events or data for evaluation.
- Business process automation, which involves the automation of an array of business tasks.
- Computer vision, which involves digitizing and analyzing images to inform an ML model's predictions or decision-making.
- Medical diagnostics, which involves identifying medical conditions and suggesting treatments.
- Predictive analytics, which involves creating models that can accurately forecast events, behaviors and trends.
- Recommendation engines, which suggest content to users based on their behavior.
- Supply chain management, which involves optimizing supply chain processes and addressing disruptions.
- Threat detection, which includes identifying instances of fraud, malware and other security threats.
In contrast, NLP offers a narrower set of language-specific applications, such as the following:
- Machine translation, which enables computer systems to translate input text from one language to another.
- Natural language generation, which enables computer systems to generate language output and underpins many generative AI architectures, including OpenAI's GPT model series.
- Text classification, which involves classifying text into different categories based on tagging.
- Text extraction, which involves pulling important pieces of data to create summaries and analysis.
Challenges
ML has many benefits and has played a significant role in the progress of AI in recent decades. However, ML comes with its fair share of challenges.
For one, many ML models and systems are expensive. They require high-quality data -- and a lot of it. Collecting and labeling that data can be costly and time-consuming for businesses. Moreover, the complex nature of ML necessitates employing an ML team of trained experts, such as ML engineers, which can be another roadblock to successful adoption. Lastly, ML bias can have many negative effects for enterprises if not carefully accounted for.
Because NLP often utilizes ML algorithms, it faces similar challenges related to complexity, cost and bias. However, NLP also comes with another challenge: the nuance of human language.
Language is complex -- full of sarcasm, tone, inflection, cultural specifics and other subtleties. The evolving quality of natural language makes it difficult for any system to precisely learn all of these nuances, making it inherently difficult to perfect a system's ability to understand and generate natural language.
Olivia Wisbey is associate site editor for TechTarget Enterprise AI. She graduated with Bachelor of Arts degrees in English literature and political science from Colgate University, where she served as a peer writing consultant at the university's Writing and Speaking Center.






