
sdecoret - stock.adobe.com
How to detect bias in existing AI algorithms
While enterprises can't eliminate bias from their data, they can significantly reduce bias by establishing a governance framework and employing more diverse employees.

Bias is a part of our human nature. We each have preferences, likes and dislikes, and different points of view. It's no surprise, then, that these preferences, or biases, are found in data.
If left unchecked, biased data can create skewed or inaccurate machine learning (ML) models.
Data helps organizations understand their customers, manage their resources, optimize operations and deal with daily changes in the market. As organizations increasingly adopt AI and ML, this data becomes more important than ever. However, data can also introduce biases into ML models, and these biases may be hard to spot and detect.
Bias can creep into algorithms in several ways and can be introduced during each stage of the AI process. From data collection efforts to data processing, analysis to modeling, each step presents different challenges and opportunities to introduce bias into an ML model, training data set or analysis unknowingly.
Common forms of bias in AI algorithms
Organizations need to recognize a range of biases in their data that can end up in their machine learning models. Knowing the types of bias that can exist can help organizations identify and potentially resolve some of the issues resulting in skewed, inaccurate or inappropriate results for the machine learning models.
Many modern organizations collect data in different forms, or modalities, such as numerical, text, images, graphs or audio, in structured and unstructured formats.
The way organizations collect their data can introduce bias, and there can be bias in the language used in each of these different data formats. For example, a mislabeled graph can lead to incorrect input data, resulting in skewed conclusions from a machine learning model.
Data collection commonly suffers from various biases resulting in the overrepresentation or underrepresentation of certain groups or categories. This is especially the case when multiple data sets are combined for use in aggregate. It's possible to spot anomalies for smaller datasets, but it becomes extremely difficult to spot anomalies for large datasets consisting of millions or billions of data points.
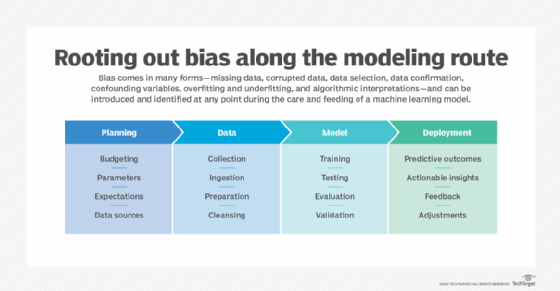
This results in models that exhibit bias favoring or disfavoring certain categories of data. Modeling bias can occur when certain data types are overrepresented in data, or conversely, when other data types are underrepresented based on their actual occurrence in the real-world data set.
There are many ways in which this sort of bias can find its way into data sets. Common biases found in data that companies can look out for include the following:
- Selection bias, in which certain individuals, categories or groups of individuals are more likely to be selected based on the problem area or means of data collection.
- Exclusion bias, in which certain individuals, categories or groups of individuals are excluded from selection either intentionally or unintentionally based on methods of data collection.
- Reporting bias, in which certain observations are more or less likely to be reported based on the nature of that data, resulting in data sets that don't represent reality.
- Confirmation bias, in which human data collectors or analysts skew their data collection methods and analysis in a way that is manipulated or misrepresented to prove a predetermined assumption with a tendency to focus on information that confirms one's preconceptions.
In one example that touched on several of these types of biases, Amazon created an experimental recruitment model that favored male candidates over female candidates. A large proportion of previous hires had been males, which skewed the model's decisions. Amazon scrapped the model before putting it into practice.
Similarly, when Apple introduced its Apple Card in 2019, its algorithm seemed to offer smaller lines of credit to women than to men.
How to detect bias in your data
AI systems learn to make decisions based on training data, which can include biased human decisions or reflect historical or social inequities, even if variables such as gender, race, geographic location or sexual orientation are removed.
By understanding common data biases, companies can better detect and reduce bias in their data.
Organizations should look at reducing the possibility of biased data sets in all phases of their data pipeline.
Data bias in data collection. The data collection process has many opportunities to introduce bias in data, as not all data has equal representation of data elements. Some sources may provide incomplete data, while some sources may not be representative of the real world or your modeling data set.
Data bias in data preparation. Data processing, including data preparation and data labeling, can also introduce biases. Data preparation includes the removal or replacement of invalid or duplicate data. While this can help remove irrelevant data from training sets, enterprises run the risk of accidentally removing important data. Data anonymization, which removes identifiable information such as race or gender, helps protect people's privacy and makes it more difficult to detect or reverse bias on those variables.
Data bias in data labeling. Data labeling is the process of adding labels to unstructured data so a computer can process and make sense of this data. However, data labeling relies on a combination of technology and people. If a human data labeler mislabels an image or uses their own discretion for translation or tagging, it could introduce bias into the data. To minimize mistakes, organizations should ensure they have checks and balances in place and don't rely solely on one data labeler or system for all human-based data labeling decisions.
Bias in data modeling techniques. AI models are subject to false positives and false negatives. It's important to keep these measures in view when looking at whether data exhibits bias, especially when particular groups exhibit over-sensitivity to false positives or false negatives. By exploring multiple modeling techniques, multiple algorithms, the use of ensemble models, changes to hyperparameters and other factors, organizations can achieve higher levels of model accuracy and precision.
Governance structures and ethical frameworks
It's impossible to fully eliminate bias from data, no matter how diligent a company is about finding bias. As such, companies should create governance structures and ethical frameworks that can provide organizational oversight of key operations and help make people aware of potential issues of data bias.
Before deploying business or mission-critical models to real-world production, organizations need to establish processes and practices to identify and then mitigate bias in AI algorithms and systems and manage models that might have unforeseen risks due to bias. Organizations should fully establish these practices in their AI governance framework.
These governance structures are often multi-pronged approaches that include a technical component that allows tools to help identify potential sources of bias and reveal the data's traits that impact the accuracy of models. These tools can also indicate how organizations can understand data collection and operations, identify potential points of bias introduction and make sure these are transparently presented.
Companies should also add more diversity to their teams. Doing so will incorporate different cultures and different points of view, which can help to greatly reduce bias. Companies can also consult and engage with social scientists, philosophers and other relevant experts to better understand and account for various perspectives.
While data bias might be unavoidable, organizations can still mitigate data bias issues that negatively impact their model outcomes.







