AI parameters: Explaining their role in AI model performance
What is the correlation between the number of parameters and an AI model's performance? It's not as straightforward as the parameter-rich generative AI apps would have us believe.

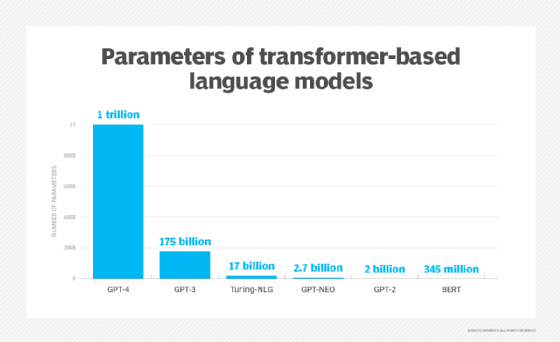
Recent progress in AI has been driven by large language models with billions and even trillions of parameters. AI parameters -- the variables used to train and tweak LLMs and other machine learning models -- have played a crucial role in the evolution of generative AI. More parameters have enabled the ability of new generative AI apps like ChatGPT to produce human-like content -- feats that were not possible only a few years ago. Sometimes, parameters are called features or feature count.
It seems reasonable to correlate the power of AI models with the number of parameters, much like we do with horsepower in cars. But more parameters is not necessarily better in some cases, and they can add extra overhead or create new problems like overfitting.
In addition, there are many ways to increase the number of parameters in AI models -- and they don't always lead to the same improvements. For example, Google's Switch Transformers scaled to trillions of parameters to test the limits of parameter count, but they were not necessarily better than some of the company's smaller models for common use cases. So, it becomes important to consider other metrics when evaluating different AI models.
Indeed, the jury is still out on how to quantify the performance of these massively scaled large language models (LLMs), said John Blankenbaker, principal data scientist at SSA & Company, a global management consulting firm. Making models larger does seem to allow them to reproduce their training outputs more faithfully, so some measures of performance will improve, he said. But the correlation of parameters and intelligence is clouded by a lot of wishful thinking, he added.
This article is part of
What is enterprise AI? A complete guide for businesses
 John Blankenbaker
John Blankenbaker
"These models are tuned to sound like they know what they are talking about without actually knowing anything about the world. I do not believe that any 'emergent' properties, such as consciousness, have appeared or are likely to appear, although there seem to be plenty of people who seem to be saying, 'Just wait until we have 10 times as many parameters.'"
Finally, further complicating matters for most enterprises is the counterintuitive nature of the term parameter itself. A parameter is not a word, feature or unit of data. It's more like a knob in a giant Rube Goldberg machine that is loosely connected to the problem you are trying to solve. Moreover, the concept of parameters as understood in LLMs is different from the parameters used in regression models.
 Sanjay Srivastava
Sanjay Srivastava
Sanjay Srivastava, chief digital strategist at Genpact, said that if nothing else, the rise of LLMs has reset expectations. "Just a couple of years ago, we thought of a Boolean parameter model as big. Today our smallest [LLM] model has seven and a half billion parameters."
What is an AI parameter?
One way to understand AI parameters is to picture a cartoon representation of a deep learning neural network with lots of knobs that are wired together. When you present an input to the neural net (say a sentence or an image), these knobs control an enormous number of very simple computations that transform the input into an output via a large number of intermediate steps called layers. When you want to train such a network, you repeatedly present it with an input and the desired output, and you use the difference between the actual output and the desired one as a guide to how to adjust the knobs to make the network do better on this input-output pair in the future.
For historical reasons, the value of each knob is called a parameter. Blankenbaker pointed out that this is not like a parameter in a linear regression, where the coefficient in front of labor hours might have an interpretation of fully loaded labor rate. Rather, the value of a parameter in an LLM is the measure of whether it amplifies or dampens its input in one tiny part of a giant computation. On its own, each parameter doesn't give us any clue as to what the network does or how it performs.
 Christine Livingston
Christine Livingston
Christine Livingston, managing director and leader of the AI and IoT practices Protiviti, a digital transformation consultancy, finds it helpful to think of parameters as weights in the model that can be adjusted and which provide flexibility. The model size is not just the number of parameters but also the size of the training data set. Additionally, it's important to note that more parameters may lead to overfitting models, which then may not perform as well on brand-new information.
Adnan Masood, chief AI architect at UST, observed that parameters affect the model's precision, accuracy and data management requirements, since they are built upon the data used to train the model. For example, in the case of a demand forecasting model, parameters help it weigh the importance of historical sales data, seasonality, economic indicators, market trends, promotional activities, pricing strategies, product lifecycle stages and external factors.
 Adnan Masood
Adnan Masood
However, in the case of LLMs, their sheer size makes it virtually impossible to care so much about specific parameters. Instead, developers look at the model holistically on factors such as the model's purpose, performance metrics, intended use cases, potential limitations, biases and ethical considerations. Understanding the underlying data set collection, the pre-processing and cleaning steps, data set characteristics, data source, possible biases, licensing and intended use cases for the data helps make the model more transparent.
Parameters vs. words vs. tokens
The meaning of parameters, tokens and words is sometimes conflated, but the terms mean different things. Saying that GPT3 was trained on 175 billion parameters does not mean it was trained to support 175 billion words. Rather a model parameter is a value learned during the training process. Parameters are learned from the tokens that are inferred from the arrangement of words.
From a practical standpoint, Masood said, a token is part of a word. The typical word-to-token ratio is 3-to-4, i.e., 100 tokens is about 75 words. Now all these tokens become embeddings (vectorized versions of words) on which the model is trained.
This training yields parameters of weights and biases. Weights are the parameters that determine the importance or strength of the connections between the input features and the output predictions in a model. Biases are additional offset parameters that allow the model to shift the output predictions up or down by a constant value.
"So, when we say 175 billion parameters, these weights and biases are what we are referring to," Masood said. These biases are added to the weighted sum of inputs at each neuron before applying the activation function to get the results.
Importance of parameters for developers and users
When people say one AI model has billions of parameters while another has trillions, what does that mean for users and developers? Masood said more parameters generally means the model has a higher capacity to learn from the data, but it also implies increased complexity, training time and computational resources.
Bigger models, i.e., ones with more parameters, can be more accurate in some cases due to their increased capacity to learn from data. However, they are typically harder to program, store, fine-tune and run, requiring more computational power, memory and expertise. Performance might be better for users but response times can be slower, and inference and training costs higher. For developers, deploying a bigger model might require training more resources. For auditors, it means black box models that don't lend themselves easily to explainable, transparent and auditable AI.
Indeed, Masood finds that smaller models are often preferred for domain-specific tasks (finance, retail, healthcare, vision etc.) due to their better generalization, faster training and inference, easier interpretability and lower data requirements. These models are custom trained on domain-specific data sets, reduce the risk of overfitting and can be trained effectively with limited data.
For edge-based inference, these models are well-suited for time-sensitive or resource-constrained environments. They are easier to adapt, which allows developers to fine-tune to meet the unique needs of a specific domain, resulting in good performance, explainability and transparency in decision-making processes.
Blankenbaker agreed that large models will likely cost more to run, but most users will access them via an API, so the cost will be priced into that. For those users who need to run models on the edge, say in a dedicated device, there appear to be ways to prune models by eliminating parameters that aren't as important without severe drops in performance. Neural Magic is a company that seems to be a strong proponent of this approach.
Challenges of fine-tuning parameters
One of the biggest challenges with the largest models is that they must be tuned for specific domains. Livingston said that large models do not have domain specificity in responses and are less focused on deeply understanding a problem domain or industry. They may also suffer from overfitting, which means they will perform very well on tests during training cycles, but when exposed to new information, they may not perform well.
Masood said this has given rise to training-run babysitters that look for unintended surprises such as jailbreak, out-of-domain Q&A, distribution shift and balancing between fine-tuning vs. in-context prompting for the use cases.
Better metrics
It is tempting to default to feature count a common synonym for parameters, as a measure of AI model performance. But it's not practical for most enterprise use cases.
"There are various better alternatives for comparing the merits of different AI models which focus on a comprehensive and holistic evaluation approach," Masood said. "No serious academic or professional uses the sheer number of parameters to judge a model."
One alternative is Stanford's HELM (Holistic Evaluation of Language Models), which considers multiple factors like accuracy, calibration, robustness, fairness, bias, toxicity and efficiency. In addition to HELM, industry practitioners utilize benchmarks like Pile, GLUE, SuperGLUE, MMLU, LAMBADA and the Big-Bench Benchmark, as well as sentence embedding methods like SBERT and USE/GOOG for evaluating LLMs on specific tasks.
"These benchmarks are essential because they help us understand AI model performance more thoroughly, addressing not only accuracy but also crucial factors like fairness, speed, cost, transparency and ethical considerations," Masood said.
Better yet, an ensemble of evaluation methods can help enterprises make more informed decisions when choosing AI models for particular tasks, striking the right balance between performance, resource requirements and ethical aspects.
Livingston recommends enterprises evaluate models for the specific use case they are trying to enable through small prototypes. "You may see some surprising results," she said.
The model architecture is also a consideration for sensitive data processing and training data consumption. The ability to fine-tune or adjust the model to fit your specific use case is also a key consideration.
Future trends
Three important trends are shaping how we think about parameters as a measure of AI performance.
First, AI developers have made considerable progress in improving the performance of AI models without having to increase the number of parameters. One meta-analysis of 231 models between 2012 and 2023 found that on average, the computing power required for subsequent versions of LLMs halved every eight months. This suggests a far faster pace of innovation compared to Moore's Law, which famously observed that the number of transistors in a chip doubled every 18 months.
Second, researchers are starting to explore new neural network approaches that could see even more impressive quality improvements relative to parameter count. For example, recent research suggests that Kolmogorov-Arnold Networks (KANs) could be a promising alternative to the multi-layered perceptron approaches commonly used today. Researchers found that for physics-related problems, a KAN approach could achieve similar performance with 10,000 times fewer parameters. That said, KANs are also much harder to train since they require CPUs running serially rather than the GPUs running in parallel with MLPs.
Third, researchers and vendors are starting to develop agentic AI frameworks that process tasks across multiple domain-specific AI agents. One good example is Salesforce's new Agentforce ecosystem. In this kind of architecture, LLMs trained on a particular domain or task could outperform general-purpose LLMs with a much larger parameter count. It's still not clear how to calculate the parameter count of each agent or their combined total across multiple interactions to a single monolithic LLM.
George Lawton is a journalist based in London. Over the last 30 years, he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.







