What is speech recognition?
Speech recognition, or speech-to-text, is the ability of a machine or program to identify words spoken aloud and convert them into readable text. Rudimentary speech recognition software has a limited vocabulary and might only identify words and phrases that are spoken clearly. More sophisticated software can handle natural speech, different accents and various languages.
Speech recognition uses a broad array of research in computer science, linguistics and computer engineering. Many modern devices and text-focused programs have speech recognition functions in them to allow for easier or hands-free use of a device. They differ from text-to-speech systems, in which the system analyses text content and converts the text into spoken audio.
Speech recognition and voice recognition are two different technologies and shouldn't be confused.
- Speech recognition is used to identify words in spoken language.
- Voice recognition is a biometric technology for identifying an individual's voice.
How does speech recognition work?
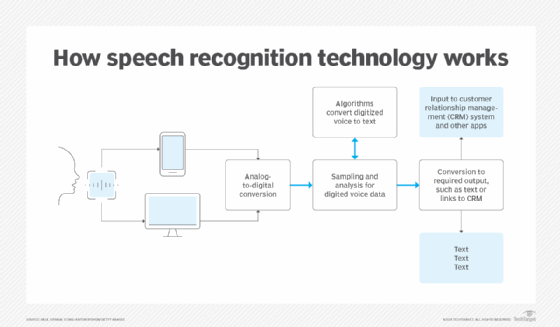
Speech recognition systems use computer algorithms to process and interpret spoken words and convert them into text. A software program turns the sound a microphone records into written language that computers and humans can understand, following these four steps:
- Analyze the audio.
- Break it into parts.
- Digitize it into a computer-readable format.
- Use an algorithm to match it to the most suitable text representation.
Speech recognition software must adapt to the highly variable and context-specific nature of human speech. The software algorithms that process and organize audio into text are trained on different speech patterns, speaking styles, languages, dialects, accents and phrasings. The software also separates spoken audio from background noise that often accompanies the signal.
To meet these requirements, speech recognition systems use two types of models:
- Acoustic models. These represent the relationship between linguistic units of speech and audio signals.
- Language models. Here, sounds are matched with word sequences to distinguish between words that sound similar.
Types of speech recognition
Speech recognition software can be either speaker-dependent or speaker-independent:
- Speaker-dependent. These platforms can achieve greater precision, although at the expense of flexibility. Initially, they must be trained by the individual who will use the software. This enables the system to recognize the user's unique speech patterns and continually improve the accuracy of its output. This type of speech recognition software is best suited for use cases like dictation and transcription.
- Speaker-independent. Anyone can use these systems. They match spoken commands and queries to a database of generic voice patterns. These platforms are more versatile -- think voice-to-text search or interactive voice response -- but they are more apt to deliver inaccurate output.
There are three types of speech recognition data. Each corresponds to the manner of input.
- Controlled. This is scripted speech, such as a menu of common commands, that the software recognizes across various pronunciations and accents. An example is of such a command is "turn off the lights."
- Semicontrolled. This is scenario-based data that provides the system with queries and commands phrased in slightly different ways. For example, you can ask for directions to a specific place using different phrasing: "Tell me how to get to the coffee shop" or "give me directions to the coffee shop" or "tell me the way to the coffee shop." Compared to controlled data, it requires more powerful content analysis before responding.
- Natural. This is unscripted, conversational speech, such as used in a phone call conversation. It requires the most complex algorithms and processing resources to render properly.
What applications use speech recognition?
Speech recognition systems have quite a few applications:
- Mobile devices. Smartphones use voice commands for call routing, speech-to-text processing, voice dialing and voice search. Users can respond to a text without looking at their devices. On Apple iPhones, for example, speech recognition powers the keyboard and Siri, the virtual assistant. Functionality is available in secondary languages, too. Speech recognition can also be found in word processing applications like Microsoft Word, where users can dictate words to be turned into text.
- Education. Speech recognition software is used in language instruction. The software hears the user's speech and offers help with pronunciation. These systems can be useful for students with disabilities, such as deafness, or neurodivergence.
- Customer service. Automated voice assistants, such as customer service chatbots or Amazon Alexa, listen to customer queries and direct them to common resources. Some systems offer a menu of prescribed options, whereas others invite the customer to state the issue they need addressed. Conversely, speech recognition software can be used to transcribe customer-agent conversations, which can be analyzed individually or in aggregate to identify sentiments and trends.
- Healthcare applications. Healthcare providers use speech recognition software to transcribe notes into patients' medical records, which can significantly relieve the burden of clinical documentation. Accuracy is important in healthcare, because a mistaken speech-to-text output could result in a medication error or incorrect diagnosis.
- Financial services. Bank customers conduct transactions by speaking to a customer application, such as a contact center or customer relationship management system, using a smartphone or at a branch office. The system may need to learn and authenticate the user's voice through a voice recognition element.
- Disability assistance. Speech recognition software translates spoken words into text using closed captions or subtitles to enable a person with hearing loss to understand what others are saying. Speech recognition can also enable those with limited use of their hands to work with computers, using voice commands instead of typing to more efficiently navigate advanced systems and workflows.
- Court reporting. Software can be used to transcribe courtroom proceedings, augmenting or replacing human transcribers.
- Dictation. Speech recognition systems let a speaker talk into a microphone and render a verbatim transcription. When complemented with generative artificial intelligence, digital correspondence and content creation can proceed quickly and efficiently in real time.
- Emotion recognition. This technology analyzes vocal characteristics to determine what emotion the speaker is feeling. Paired with sentiment analysis, this can reveal how someone feels about a product, service, company or other entity.
- Hands-free communication. Drivers use voice control to manage phone functions, music and GPS navigation, among other tasks, without having to touch their mobile device or vehicle control panel.

What are the features of speech recognition systems?
Good speech recognition programs let users customize them to their needs. The features that enable this include the following components:
- Language weighting. This feature tells the algorithm to give special attention to certain words, such as those spoken frequently or ones that are unique to the conversation or subject. For example, the software can be trained to listen for specific product references.
- Acoustic training. Speech recognition software tunes out ambient noise that pollutes spoken audio data. Software programs with acoustic training can distinguish a speaker's style, pace and volume amid the din of many people speaking in an office.
- Speaker labeling. This capability enables a program to label individual participants and identify their specific contributions to a conversation.
- Profanity filtering. The software filters out undesirable and offensive words and language.
- Managing bias. Speech recognition systems are continually enhanced to recognize a broader range of accents and languages to ensure fairness, provide greater access to technology and eliminate bias.
- Data protection. In situations where users speak personally identifiable information -- such as date of birth, Social Security number, account number or phone number -- the converted data is protected using data encryption. This helps ensure compliance with regulations such as the European Union's General Data Protection Regulation and the Health Insurance Portability and Accountability Act.
What are the different speech recognition algorithms?
The power behind speech recognition features comes from a set of algorithms and technologies. They include the following:
- Hidden Markov model. HMMs are used in autonomous systems where a state is partially observable or when all the information necessary to make a decision isn't immediately available to the sensor, such as a microphone in speech recognition's case. An example of this is in acoustic modeling, where a program must match linguistic units to audio signals using statistical probability.
- Natural language processing. NLP eases and accelerates the speech recognition process.
- N-grams. This simple approach to language models creates a probability distribution for a sequence. An example would be an algorithm that looks at the last few words spoken, approximates the history of the sample of speech and uses that to determine the probability of the next word or phrase that will be spoken.
- Artificial intelligence. AI and machine learning methods like deep learning and neural networks are common in advanced speech recognition software. These systems use grammar, structure, syntax and composition of audio and voice signals to process speech. Machine learning systems gain knowledge with each use, making them well suited for nuances like accents.
Advantages of speech recognition
There are several advantages to using speech recognition software:
- Machine-to-human communication. Speech recognition technology enables electronic devices to communicate with humans in natural language or conversational speech.
- Readily accessible. This software is frequently installed on computers and mobile devices, making it accessible.
- Easy to use. Well-designed software is straightforward to operate and often runs in the background.
- Continuous, automatic improvement. Speech recognition systems that incorporate AI become more effective and easier to use over time. As systems complete speech recognition tasks, they generate more data about human speech and get better at what they do.
Disadvantages of speech recognition
While convenient, speech recognition technology still has some limitations:
- Inconsistent performance. The systems may be unable to capture words accurately because of variations in pronunciation, lack of support for some languages and inability to sort through background noise. Ambient noise can be especially challenging. Acoustic training can help filter it out, but these programs aren't perfect. Sometimes, it's impossible to isolate the human voice.
- Speed. Some speech recognition programs take time to deploy and master. The speech processing may feel relatively slow.
- Source audio file issues. Speech recognition success depends on the recording equipment used, not just the software.
Speech recognition evolution and future
Speech recognition is an evolving technology. It's one of the ways people can communicate with computers with little or no typing. A variety of communications-based business applications capitalize on the convenience and speed of spoken communication that this technology enables.
In the early days of speech recognition, the primary limiting factors were computer processing speeds and memory size. Algorithms such as HMM had been developed and tested in the 1980s, but computers weren't powerful enough to handle compute-intensive automatic speech recognition (ASR). With the advent of microprocessors, cloud computing and enhanced automation of ASR technologies, those restrictions have disappeared.
Continued development of NLP and large language models -- augmented by AI, machine learning and neural networks -- has dramatically improved ASR performance. Multiple languages, accents and unique speech characteristics, plus faster conversion speeds, make speech recognition an increasingly valuable and viable tool.
Speech recognition programs have advanced greatly over 60 years of development, and they're still improving. Widespread adoption of advanced generative AI systems like OpenAI's ChatGPT are likely to become closely intertwined with speech recognition technology.
AI is changing speech recognition technology in many different ways. Find out the latest AI-driven speech recognition trends and use cases.






