
peshkova - Fotolia
A history and timeline of big data
Milestones that led to today's big data revolution -- from 1600s' statistical analysis to the first programmable computer in the 40s to the internet, Hadoop, IoT, AI and more.
Big data has revolutionized the modern business environment in recent years. A mixture of structured, semistructured and unstructured data, big data is a collection of information that organizations can mine for business purposes through machine learning, predictive modeling, and other advanced data analytics applications.
At one time the concept of big data may have seemed like a buzzword, but the reality is the impact of big data on the world around us has been tremendous. As you will see from this timeline covering the history of big data, big data analytics builds on concepts that have been around for centuries.
The history data analysis that led to today's advanced big data analytics starts way back in the 17th century in London. Let's begin our journey.
The bedrock of big data
A foundational period where clever people started seeing the value of turning to statistics and analysis to make sense of the world around them.
1663
John Graunt introduces statistical data analysis with the bubonic plague. The London haberdasher published the first collection of public health records when he recorded death rates and their variations during the bubonic plague in England.
1865
Richard Millar Devens coins the term "business intelligence." As we understand it today, business intelligence is the process of analyzing data, and then using it to deliver actionable information. In his "Cyclopædia of Commercial and Business Anecdotes," Devens described how a banker used information from his environment to turn a profit.
1884
Herman Hollerith invents the punch card tabulating machine, marking the beginning of data processing. The tabulating device Hollerith developed was used to process data from the 1890 U.S. Census. Later, in 1911, he founded the Computing-Tabulating-Recording Company, which would eventually become IBM.
1926
Nikola Tesla predicts humans will one day have access to large swaths of data via an instrument that can be carried "in [one's] vest pocket." Tesla managed to predict our modern affinity for smartphones and other handheld devices based on his understanding of how wireless technology would change particles: "When wireless is perfectly applied, the whole earth will be converted into a huge brain, which in fact it is, all things being particles of a real and rhythmic whole. We shall be able to communicate with one another instantly, irrespective of distance."
1928
Fritz Pfleumer invents a way to store information on tape. Pfleumer's process for putting metal stripes on magnetic papers eventually led him to create magnetic tape, which formed the foundation for video cassettes, movie reels and more.
1943
The U.K. created a theoretical computer and one of the first data processing machines to decipher Nazi codes during WWII. The Colossus, as it was called, performed Boolean and counting operations to analyze large volumes of data.

1959
Arthur Samuel, a programmer at IBM and pioneer of artificial intelligence, coined the term machine learning (ML).
1965
The U.S. plans to build the first data center buildings to store millions of tax returns and fingerprints on magnetic tape.
1969
Advanced Research Projects Agency Network (ARPANET), the first wide area network that included distributed control and TCI/IP protocols, was created. This formed the foundation of today's internet.
The internet age: The dawn of big data
As computers start sharing information at exponentially greater rates due to the internet, the next stage in the history of big data takes shape.
1989 and 1990
Tim Berners-Lee and Robert Cailliau found the World Wide Web and develop HTML, URLs and HTTP while working for CERN. The internet age with widespread and easy access to data begins.
1996
Digital data storage becomes more cost-effective than storing information on paper for the first time in 1996, as reported by R.J.T. Morris and B.J. Truskowski in their 2003 IBM Systems Journal paper, "The Evolution of Storage Systems."
1997
The domain google.com is registered a year before launching, starting the search engine's climb to dominance and development of numerous other technological innovations, including in the areas of machine learning, big data and analytics.
1998
Carlo Strozzi develops NoSQL, an open source relational database that provides a way to store and retrieve data modeled differently from the traditional tabular methods found in relational databases.
1999
Based on data from 1999, the first edition of the influential book, How Much Information, by Hal R. Varian and Peter Lyman (published in 2000), attempts to quantify the amount of digital information available in the world to date.
Big Data in the 21st century
Big data as we know it finally arrives, and the explosion of ingenuity that it brings with it cannot be overestimated. Everyone, and everything, is impacted.
2001
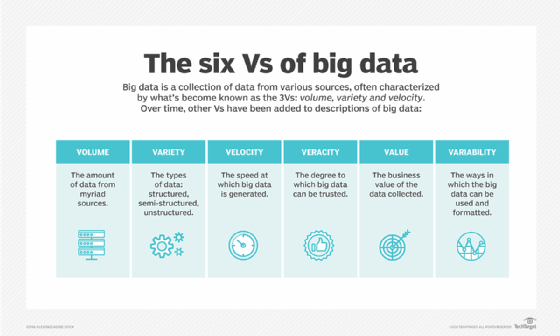
Doug Laney of analyst firm Gartner coins the 3Vs (volume, variety and velocity), defining the dimensions and properties of big data. The Vs encapsulate the true definition of big data and usher in a new period where big data can be viewed as a dominant feature of the 21st century. Additional Vs -- such as veracity, value and variability -- have since been added to the list.
2005
Computer scientists Doug Cutting and Mike Cafarella create Apache Hadoop, the open source framework used to store and process large data sets, with a team of engineers spun off from Yahoo.
2006
Amazon Web Services (AWS) starts offering web-based computing infrastructure services, now known as cloud computing. Currently, AWS dominates the cloud services industry with roughly one-third of the global market share.

2008
The world's CPUs process over 9.57 zettabytes (or 9.57 trillion gigabytes) of data, about equal to 12 gigabytes per person. Global production of new information hits an estimated 14.7 exabytes.
2009
Gartner reports business intelligence as the top priority for CIOs. As companies face a period of economic volatility and uncertainty due to the Great Recession, squeezing value out of data becomes paramount.
2011
McKinsey reports that by 2018 the U.S. will face a shortage of analytics talent. Lacking between 140,000 and 190,000 people with deep analytical skills and a further 1.5 million analysts and managers with the ability to make accurate data-driven decisions.
Also, Facebook launches the Open Compute project to share specifications for energy-efficient data centers. The initiative's goal is to deliver a 38% increase in energy efficiency at a 24% lower cost.
2012
The Obama administration announces the Big Data Research and Development Initiative with a $200 million commitment, citing a need to improve the ability to extract valuable insights from data and accelerate the pace of STEM (science, technology, engineering, and mathematics) growth, enhance national security and transform learning. The acronym has since become STEAM, adding an A by incorporating the arts.
Harvard Business Review names data scientist the sexiest job of the 21st century. As more companies recognized the need to sort and gain insights from unstructured data, demand for data scientists soared.
2013
The global market for big data reaches $10 billion.
2014
For the first time, more mobile devices access the internet than desktop computers in the U.S. The rest of the world follows suit two years later, in 2016.
2016
Ninety percent of the world's data was created in the last two years alone, and IBM reports that 2.5 quintillion bytes of data is created every day (that's 18 zeroes).
2017
IDC forecasts big data analytics market would reach $203 billion in 2020.
2020
Allied Market Research reports the big data and business analytics market hit $193.14 billion in 2019, and estimates it will grow to $420.98 billion by 2027 at a compound annual growth rate of 10.9%.
Edge computing set to revise how data is managed and processed for critical sectors of the economy. Edge computing, which refers to computing done near the source of data collection rather than in the cloud or a centralized data center, represents the next frontier for big data.
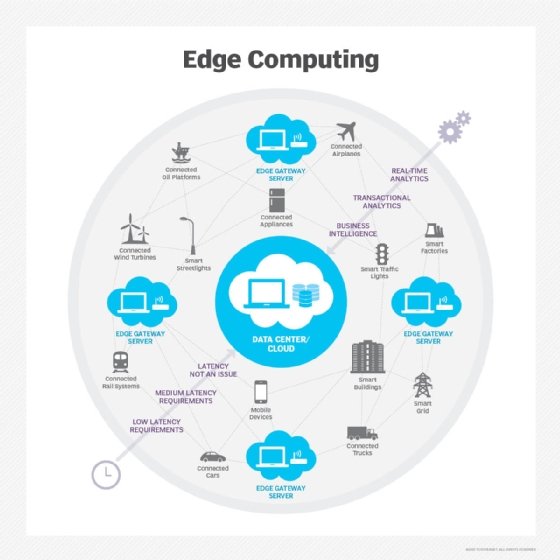
The future of big data: Where does big data go from here?
Due to the explosion of connected devices, our increasing reliance on the cloud and the coming edge computing revolution, among other factors, big data has a lot of growing left to do.
Technologies such as machine learning, AI and IoT analytics, for example, continue to push the envelope by vastly improving our ability to process, analyze and act upon data.
Expect significant advancements in big data and analytics to happen at a faster clip. The next few years could very well make what we've seen over the last 20 years look like child's play.







