Getty Images/iStockphoto
How to scrape data from a website
Web scraping is about combing through data at scale. AI developers do it, search engines do it and you can too with a few lines of Python.


"Hey ChatGPT, write me a pun about web scraping."
"Why did the web scraper get kicked out of school? It kept skipping classes!" Get it? Like an HTML class.
Not bad, ChatGPT. It only took about 570 gigabytes of data scraped from the public internet and years of development to come up with that one.
ChatGPT, the large language model that powers it and similar AI systems were trained by synthesizing data collected during large-scale web scraping. This has caused many -- including authors and social media platforms – to reexamine data rights and ownership as AI models use data that they provided for free.
Although AI is the new context for it, web scraping is actually an old practice -- about as old as the web itself. Just like the web, scraping has grown significantly, both in scale and sophistication. Web scraping is the technique that has powered search engines since their inception.
Before Google was around, the Internet Archive scraped the web to archive it and continues to do so. As of 2023, the Wayback Machine -- the Internet Archive's record of the web -- has archived more than 833 billion webpages. Scraping has been, is and will continue to be a cornerstone of the internet for the foreseeable future.
What is web scraping?
Web scraping is also known as web harvesting and web data harvesting. It refers to the process of programmatically reading and analyzing content on the internet. There are three main steps to web scraping:
- Mining data. Mining data involves finding the source and pulling the data from that source into an environment where the user can manipulate it -- an independent development environment (IDE), for example.
- Parsing data. Parsing data involves reading and filtering it for bits of value. Think of prospecting through a sieve for gold.
- Outputting data. Outputting data involves taking the harvested data out of the IDE and applying it to whatever the user wants it for.
Web scraping usually refers to extracting, parsing and outputting data from HTML code. Webpages typically comprise a combination of HTML, CSS and JavaScript code. A browser makes these elements human-readable. By right-clicking and inspecting a page, a user can see which on-page elements in the browser correspond to which lines of HTML code. This can be helpful in knowing what to scrape.
Although HTML is the code being sorted in web scraping, any type of data can be harvested.
Web scraping use cases
There are many common use cases for web scraping across industries, including the following:
- Price monitoring and comparison. Retailers and e-commerce businesses scrape competitor websites to monitor and compare prices.
- Stock market analysis. Financial analysts scrape stock market websites to gather data on stock prices, company news and financial statements for analysis and forecasting.
- Real estate listings. Real estate companies scrape property websites to gather data on property listings, prices and market trends.
- Job board monitoring. Recruitment agencies and HR departments scrape job boards to find new job listings that match specific criteria.
- News and content aggregation. Media companies and news aggregators scrape various news sites to gather and curate content for their platforms.
- Lead generation. Businesses scrape websites to gather potential lead contact information -- such as email addresses and phone numbers.
- Research and academia. Researchers scrape websites to gather data for academic studies, market research and other analytical purposes.
- Journalism. Journalists scrape the web for data to inform their stories and to verify facts.
- Travel and hospitality. Travel agencies and aggregators scrape airline, hotel and other travel-related websites to gather data on flight schedules, room availability and prices.
- Social media marketing. Brands and marketers scrape social media platforms to monitor mentions of their brand, track sentiment and gather insights on customer preferences.
- SEO. SEO professionals scrape search engine results pages to monitor keyword rankings and analyze competitors' SEO strategies.
- Event monitoring. Companies scrape event websites to gather data on upcoming events, conferences and seminars in their industry.
- Product sentiment. E-commerce businesses scrape product review sites to monitor customer feedback and sentiment about their products.
- Legal and compliance. Companies scrape websites to ensure their content is not being used without permission or to monitor for counterfeit products.
- Data integration. Developers scrape websites to integrate data from those sites into their applications. This is how training data is amassed for AI and large language models.
- Sports statistics. Sports analysts and enthusiasts scrape websites to gather data on player statistics, game results and team performances.
- Threat intelligence. Web scraping can help gather intelligence to minimize, manage and mitigate cyber attacks.
Is scraping the web illegal?
Scraping the web for publicly available data is legal within certain guidelines. Web scraping is not the same thing as stealing data. There is no federal law against web scraping and many legitimate businesses rely on it to make money. Some platforms -- such as Reddit -- provide access to an application programming interface (API) that makes the platform easier to scrape. Until recently, Reddit offered this service for free.
However, there are cases when web scraping is illegal, such as when data is taken without permission. If web scraping violates a website's terms of service, the Computer Fraud and Abuse Act, data protection laws such as the General Data Protection Regulation or certain copyright laws, it can lead to legal action.
Many social platforms seek to limit access to their data to discourage scrapers. LinkedIn is one platform that actively discourages it.
One example of a conflict that arose from web scraping is the case of HiQ vs. LinkedIn. In 2017, data analytics company HiQ Labs sued LinkedIn after receiving a cease-and-desist letter from LinkedIn prohibiting web scraping of its public profiles. The court granted HiQ a preliminary injunction, allowing it to continue scraping, emphasizing the public nature of the data and potential anticompetitive effects of LinkedIn's actions.
LinkedIn uses deep learning to detect bot-like behavior and inform members that get flagged on how they can correct their behavior.
Some other ways that platforms can discourage or avoid scraping include the following:
- Rate limit requests. Scrapers and bots can access webpages automatically, faster than any human can. A rate limiter enforces a maximum number of requests that an IP address can make in a given window of time.
- Modify HTML regularly. Scrapers typically rely on consistent HTML structure to identify patterns in valuable data and extract it. Changing these patterns can make it harder for a scraper to extract valuable data.
- Use CAPTCHAs. CAPTCHAs force the browser -- human or bot -- to solve a challenge that proves they are a human. Many scrapers will not be able to solve a CAPTCHA.
Many websites have a robots.txt file. It's a page directed at web crawlers that specifies how the page is allowed to be crawled, and what's against the rules. It provides information such as allowed content, disallowed content, sitemaps to make crawling easier for search engines and crawl-delays to tell bots how long to wait between consecutive requests.
The robots.txt file is typically located at the root of the website. Here is Bloomberg's robots.txt file as a real-world example.
Ways to scrape a website
There are many ways to scrape a website, with varying levels of coding ability required.
No-code ways to scrape include the following:
- Manual copy and paste. The most straightforward way to scrape data from a website is to manually copy data from the source and analyze it.
- Browser developer tools. Browsers have many built-in tools to inspect and extract website elements. One example is the inspect function, which shows the website's underlying source code.
- Browser extensions. Browser extensions can be added to a browser to perform specific, pattern-based web scraping.
- RSS feeds. Some websites offer lists of structured data in the form of RSS feeds.
- Web scraping services. Services such as Diffbot, Octoparse, Import.io and ParseHub are no-code scraping platforms.
- Data mining software. Software such as KNIME and RapidMiner offer a comprehensive suite of data science and analytics features that include web scraping.
Ways to scrape that involve some coding include the following:
- Beautiful Soup. Python's Beautiful Soup library is a good resource for an introduction to scraping. It requires a minimal amount of coding know-how and is good for one-off HTML scraping projects.
- APIs. Many websites provide structured APIs that let users scrape data. Using APIs often requires a basic knowledge of data formats such as JSON and XML, as well as a basic understanding of HTTP requests.
Scraping methods that require more coding knowledge include the following:
- Scrapy. Python's Scrapy library can be employed for more complex web scraping tasks. Scrapy can do a lot but can be difficult for a new user.
- JavaScript. Use the Axios JavaScript library for making HTTP requests and the Cheerio library for HTML parsing in Node.js.
- Headless browsers. Browser automation tools such as Selenium or Puppeteer can control browsers using scripts and handle sites with a lot of JavaScript content.
- Web crawling frameworks. Advanced frameworks such as Apache Nutch enable web scraping on a large scale.
How to build a web scraper in Python
Following is an example of a simple scraper. This scraper extracts definition articles from links listed on the WhatIs.com homepage using the Python libraries requests and Beautiful Soup.
Step 1. Access WhatIs.com through code
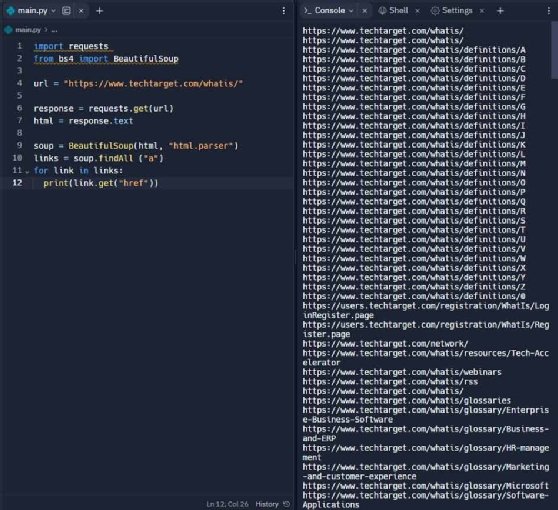
This step shows how content gets scraped into the coding environment using the requests library. The code in Figure 1 imports the first 1,000 characters of the WhatIs.com source code. It isn't a necessary precursor to the next step, but shows how the Python libraries at the top of the code pull data into the IDE.

Requests is a popular open source library for making HTTP requests. The line response.txt returns the source code from the website.
Step 2. Extract URLs
HTML links are represented with the following format:
<a href="URL">Clickable Text or Content</a>
The Whatis.com source code is full of them.
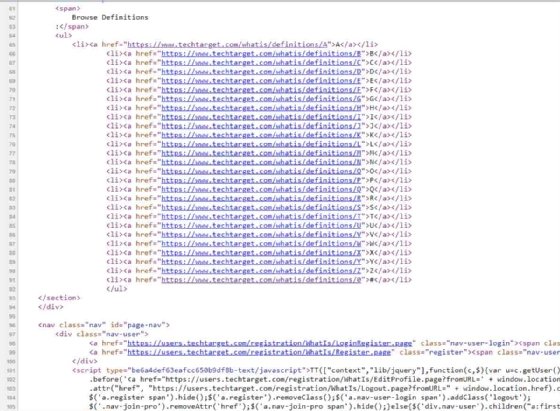
The code in Figure 3 returns a list of every link on the WhatIs.com homepage. The code does this by finding every instance of the letter "a" -- which indicates a link -- then printing the URL of that link.
As pictured, the scraper extracts every hyperlink from the page, including TechTarget's privacy page and contact page. The goal is to extract only definition URLs.
Step 3. Extract definition URLs
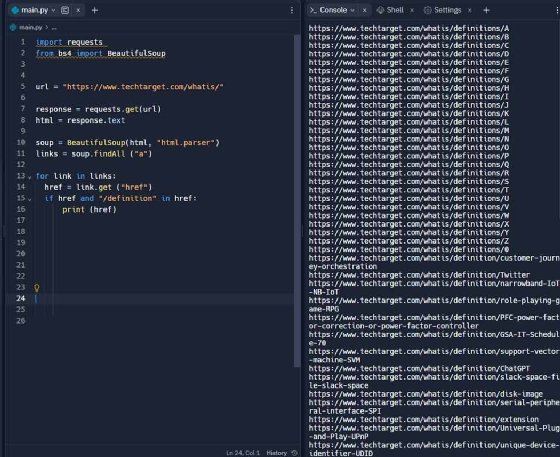
Look for a pattern in the URLs of articles that the scraper can filter for and extract. Definitions all have a similar URL structure -- they have /definition in the URL. The following code ensures that all URLs with /definition will be printed.
Step 4. Refining output
The previous step mostly worked. However, it still prints a list of links to the WhatIs.com glossary, which all contain the word "definitions." To remove the glossary entries and only display definition links, add the following line to the for loop:
if href and "/definition" in href and "/definitions" not in href:
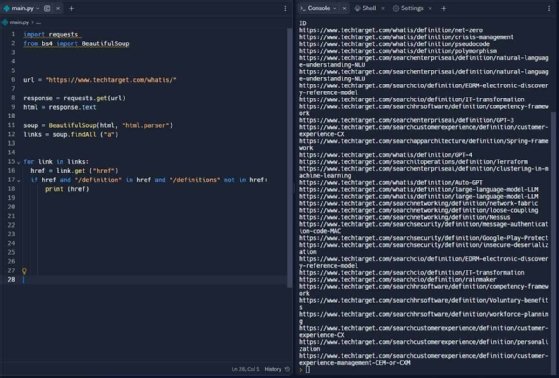
Now all the links displayed will be to TechTarget definitions, and the glossary will be excluded.
To export these links from the coding environment, use the pandas library to turn the output into a data frame, then save it to a CSV file in the coding environment with the title "output.csv." The code will look like Figure 6 with those lines of code appended.