
What is a neural network?
A neural network is a machine learning (ML) model designed to process data in a way that mimics the function and structure of the human brain. Neural networks are intricate networks of interconnected nodes, or artificial neurons, that collaborate to tackle complicated problems.
Also referred to as artificial neural networks (ANNs), neural nets or deep neural networks, neural networks represent a type of deep learning technology that's classified under the broader field of AI.
Neural networks are widely used in a variety of applications, including image recognition, predictive modeling, decision-making and natural language processing (NLP). Examples of significant commercial applications over the past 25 years include handwriting recognition for check processing, speech-to-text transcription, oil exploration data analysis, weather prediction and facial recognition.
How do artificial neural networks work?
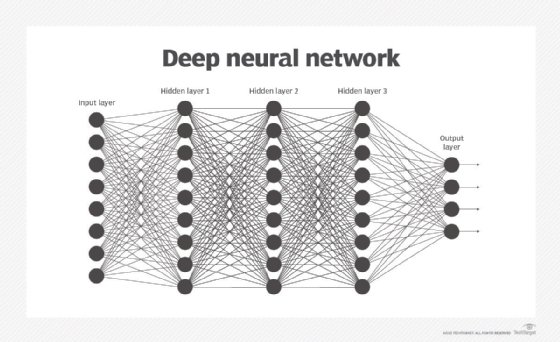
An ANN usually involves many processors operating in parallel and arranged in tiers or layers. These tiers, or layers, fall under three categories -- an input layer, a number of hidden layers, and an output layer. The first tier -- analogous to optic nerves in human visual processing -- receives the raw input information. Its job is to process, analyze, and categorize the incoming data and then pass it on to the next layer.
Instead of the original raw input, each successive tier receives the output from the preceding tier, the same way neurons further from the optic nerve receive signals from those closer to it. There may be many hidden layers in an ANN and they all function in the same way -- analyze and process the output from the previous layer and then pass it on to the next layer for further analysis and processing.
Simple neural networks have fewer hidden layers. Deep neural networks have several hidden layers and millions of interlinked neurons that may have more or less influence on the other neurons. The large number of layers and neurons allow deep ANNs to process complex problems and map any input type to any output type.
The last tier of an ANN, intuitively named the output layer, produces the system's result. This layer may have one or multiple nodes, depending on the problem being addressed by the ANN. For example, binary classification problems require only one node in the output layer, while multi-class classification problems require multiple output nodes.
Each processing node in the ANN has its own small sphere of knowledge, including what it has seen and any rules it was originally programmed with or developed for itself. The tiers are highly interconnected, which means each node in Tier N will be connected to many nodes in Tier N-1 -- its inputs -- and in Tier N+1, which provides input data for the Tier N-1 nodes. There could be one or more nodes in the output layer, from which the answer it produces can be read.
Each individual node or neuron carries information, and the connections between neurons are regulated by weights and biases (also known as thresholds). Weights are assigned to every input layer and they determine how much each variable contributes to the output. A variable with a higher weight contributes more to the output compared to variables with a lower weight.
Once the input goes through all the layers of the ANN, the output is determined. First, the inputs are multiplied by their respective weights, then they are summed. This total goes through an activation function, which determines the output. The activation function is important because it enables the neural network to learn more complex patterns over time.
Next, the output is compared to the threshold. If the output exceeds the threshold, the node is activated, and the output becomes the input for the next layer in the ANN and is passed to it for further processing. This is known as a feedforward mechanism, meaning information flows only in one direction -- from input to output.
Most ANNs are feedforward, although they can also be trained to move in the opposite direction (from output to input). This mechanism, known as backpropagation, is generally used to calculate the error associated with each neuron in the ANN and accordingly adjust the model's parameters.
ANN algorithms continuously adjust their weights and bias using reinforcement learning and a method called gradient descent. The algorithm's goal is to adjust its weights in order to reduce output errors. The more the algorithm is trained, the more its parameters adjust to further reduce errors (also known as minimizing the cost function).
ANNs are noted for being adaptive, which means they modify themselves as they learn from initial training, and subsequent runs provide more information about the world. The most basic learning model is centered on weighting the input streams, which is how each node measures the importance of input data from each of its predecessors. Inputs that contribute to getting the right answers are weighted higher.
Applications of artificial neural networks
Image recognition was one of the first areas in which neural networks were successfully applied. A specific type of ANNs called convolutional neural networks (CNNs) is used for image-related tasks, such as image recognition, pattern recognition and computer vision. CNNs include multiple hidden layers that perform mathematical functions -- specifically, functions from linear algebra -- to identify patterns and extract relevant features from input images. Different layers extract different features from the input. At the output end, the CNN recognizes the image and can even classify it as a specific type.
Computer vision technology is another useful application of ANNs. It allows ANNs to identify, extract information from, and classify both images and videos. A deep neural network that's been trained on large volumes of relevant data can perform computer vision tasks at almost the same accuracy -- and much higher speeds -- than humans. Some of the applications of computer vision include the following:
- Self-driving cars can recognize road signs, obstacles and people to adjust movement (turn, stop, swerve, etc.).
- Cameras with facial recognition capabilities can identify human faces and recognize specific attributes, like facial hair, to identify specific individuals.
- Traffic cameras can detect and flag traffic violations and intelligently manage and optimize traffic flows.
- Medical imaging machines can analyze imaging documents to capture useful insights that support diagnostic decision-making, identify tumors, monitor patient vital signs, and track patients' chronic conditions.
- Robots can identify defects in products on the assembly line or monitor equipment to flag potential issues (predictive maintenance) before they occur.
- Image labeling systems in retail can capture image details to help retailers pinpoint missing items and to provide precise search results to customers.
Apart from image and video recognition, ANNs are also used for speech recognition and NLP.
The most obvious example of ANNs recognizing and responding to human speech is their use in virtual assistants, like Apple's Siri and Amazon's Alexa. Siri and Alexa use ANNs to understand human input and, in response, perform various tasks -- play a song, send an email, show the weather, etc.
ANNs also enable computers to understand natural human language and respond in kind. NLP powered by ANNs is used in chatbots, to analyze and summarize documents containing unstructured (e.g., text or images) data, to generate new content (e.g., for marketing), and to perform customer sentiment analysis by analyzing customer content on social media and other places.
Recommendation engines also rely on ANNs to analyze a user's behavioral and preference history and, accordingly, provide personalized recommendations. Netflix and Amazon are two of the best examples of ANNs driving recommendation engines and enabling the brands to connect with customers in more personalized and scalable ways.
In general, the technology uses of neural networks have expanded from just image recognition to many additional areas, including the following:
- Chatbots.
- Computer vision.
- NLP, translation and language generation.
- Speech recognition.
- Recommendation engines.
- Stock market forecasting.
- Delivery driver route planning and optimization.
- Medical diagnosis and disease recognition.
- Drug discovery and development.
- Social media.
- Personal assistants.
- Pattern recognition.
- Sequence recognition.
- Data processing.
- Data mining
- Regression analysis.
- Process and quality control.
- Targeted marketing through social network filtering and behavioral data insights.
- Generative AI.
- Quantum chemistry.
- Data visualization.
- Email spam filtering.
- Financial modeling.
- Robotics.
- Infrastructure reliability analysis.
- Black-box modeling in geoscience.
- Cybersecurity.
- Financial fraud detection.
- Materials science research.
The prime uses of ANNs involve any process that operates according to strict rules or patterns and has large amounts of data. If the amount of data involved is too large for a human to make sense of in a reasonable amount of time, the process is likely a good candidate for automation through artificial neural networks.
How do neural networks learn? How are neural networks trained?
Training a neural network means teaching it how to perform a certain task. Typically, an ANN is initially trained or fed large amounts of data. Training consists of providing input and telling the network what the output should be. For example, to build a network that identifies the faces of actors, the initial training might be a series of pictures, including actors, non-actors, masks, statues and animal faces. Each input is accompanied by matching identification, such as actors' names or "not actor" or "not human" information. Providing the answers enables the model to adjust its internal weighting to do its job better.
For example, if nodes David, Dianne and Dakota tell node Ernie that the current input image is a picture of Brad Pitt, but node Durango says it's George Clooney, and the training program confirms it's Pitt, Ernie decreases the weight it assigns to Durango's input and increases the weight it gives to David, Dianne and Dakota.
Basically, the ANN first processes a large data set that might contain labeled or unlabeled data. This allows it to learn how to process new, previously unseen data. The more data it is trained on, the better its learning capabilities and the more accurate its output over time.
In defining the rules and making determinations -- the decisions of each node on what to send to the next layer based on inputs from the previous tier -- neural networks use several principles. These include gradient-based training, fuzzy logic, genetic algorithms and Bayesian methods. They might be given some basic rules about object relationships in the data being modeled.
For example, a facial recognition system might be instructed, "Eyebrows are found above eyes," or "Mustaches are below a nose. Mustaches are above and/or beside a mouth." Preloading rules can make training faster and the model more powerful faster. But it also includes assumptions about the nature of the problem, which could prove to be either irrelevant and unhelpful, or incorrect and counterproductive, making the decision about what, if any, rules to build unimportant.
Further, the assumptions people make when training algorithms cause neural networks to amplify cultural biases. Biased data sets are an ongoing challenge in training systems that find answers on their own through pattern recognition in data. If the data feeding the algorithm isn't neutral -- and almost no data is -- the machine propagates bias.

Types of neural networks
Neural networks are sometimes described in terms of their depth, including how many layers they have between input and output, or the model's so-called hidden layers. This is why the term neural network is used almost synonymously with deep learning. Neural networks can also be described by the number of hidden nodes the model has, or in terms of how many input layers and output layers each node has. Variations on the classic neural network design enable various forms of forward and backward propagation of information among tiers.
Specific types of ANNs include the following:
Feed-forward neural networks
One of the simplest variants of neural networks, these pass information in one direction, through various input nodes, until it makes it to the output node. The network might or might not have hidden node layers, making their functioning more interpretable. It's prepared to process large amounts of noise. This type of ANN computational model is used in technologies such as facial recognition and computer vision.
Recurrent neural networks
More complex in nature, recurrent neural networks (RNNs) save the output of processing nodes and feed the result back into the model. This is how the model learns to predict the outcome of a layer. Each node in the RNN model acts as a memory cell, continuing the computation and execution of operations.
This neural network starts with the same front propagation as a feed-forward network, but then goes on to remember all processed information to reuse it in the future. If the network's prediction is incorrect, then the system self-learns and continues working toward the correct prediction during backpropagation. This type of ANN is frequently used in text-to-speech conversions.
Convolutional neural networks
Convolutional neural networks (CNNs) are one of the most popular models used today. This computational model uses a variation of multilayer perceptrons and contains one or more convolutional layers that can be either entirely connected or pooled. These convolutional layers create feature maps that record a region of the image that's ultimately broken into rectangles and sent out for nonlinear processing.
The CNN model is particularly popular in the realm of image recognition. It has been used in many of the most advanced applications of AI, including facial recognition, text digitization and NLP. Other use cases include paraphrase detection, signal processing and image classification.
Deconvolutional neural networks
Deconvolutional neural networks use a reversed CNN learning process. They try to find lost features or signals that might have originally been considered unimportant to the CNN system's task. This network model can be used in image synthesis and analysis.
Modular neural networks
These contain multiple neural networks working separately from one another. The networks don't communicate or interfere with each other's activities during the computation process. Consequently, complex or big computational processes can be performed more efficiently.
Perceptron neural networks
These represent the most basic form of neural networks and were introduced in 1958 by Frank Rosenblatt, an American psychologist, who is also considered the father of deep learning. In fact, the perceptron is the oldest neural network.
Rosenblatt published his research about perceptrons in the 1958 paper "The Perceptron: a probabilistic model for information storage and organization in the brain." In the paper, he explained how he got the IBM 704 computer to learn how to distinguish between two sets of cards. Rosenblatt concluded the paper by suggesting that the study of perceptrons might lead to a better understanding of "those fundamental laws of organization which are common to all information handling systems."
A single-layer perceptron can only perform simple, linear computational tasks since it only has one layer of neurons between the input and output layers. This makes it unsuitable for more complex tasks.
The perceptron takes in the input, weighs it and then sums up the weights and finally produces the output. As with other ANNs, the weights and thresholds of the neurons in a perceptron are adjustable.
The perceptron is specifically designed for binary classification tasks, enabling it to differentiate between two classes based on input data. Simple single-layer perceptrons can be built using open source machine learning frameworks like TensorFlow.
Neural networks are not the same as machine learning. In fact, ANNs are a subset of the broader field of machine learning.
Multilayer perceptron networks
Multilayer perceptron (MLP) networks, also known as feedforward neural networks, consist of multiple layers of neurons, including an input layer, one or more hidden layers, and an output layer. Each layer is fully connected to the next, meaning that every neuron in one layer is connected to every neuron in the subsequent layer. Every layer transforms the received input and passes it on to the next layer until the final output is generated at the output layer. This highly interconnected neuronal architecture enables MLPs to learn complex patterns and relationships in data, making them suitable for various classification and regression tasks. MLPs can also be trained to work on parallel computing tasks.
Despite the use of the word "perceptron" in the name multilayer perceptron network, MLPs are not comprised of perceptrons but of sigmoid neurons. Also, it uses non-linear activation functions. It is these features that allow MLPs to work on complex, non-linear real-world problems, including computer vision and NLP.
One drawback of MLPs is that they are computationally expensive. Since they comprise many layers, training MLPs is a slow process. Also, MLPs are prone to overfitting, which can lead to sub-optimal generalization of new, unseen data.
Radial basis function neural networks
Radial basis function (RBF) neural networks are a type of feed-forward neural networks that use a three-layer architecture. They also have universal approximation capabilities and use radial basis functions, such as Gaussian functions, as activation functions. RBFs are typically used for non-linear function approximation and time series prediction tasks, as well as in control systems. They can learn quickly and offer efficient performance for non-linear system identification, classification and regression problems. Also, the simple architecture makes it easy to understand and implement RBF neural networks -- despite the fact that they require three-stage training.
Transformer neural networks
As one of the more cutting-edge types of neural networks, transformer neural networks are reshaping NLP and other fields through a range of advancements. Introduced by researchers from Google and the University of Toronto in a 2017 paper, transformers are specifically designed to process sequential data, such as text, by effectively capturing relationships and dependencies between elements in the sequence, regardless of their distance from one another.
One of the Google researchers also published a follow-up article in which he stated that the transformer is "a novel neural network architecture based on a self-attention mechanism that we believe to be particularly well suited for language understanding." They also explained how they enabled a transformer to outperform both CNNs and RNNs on academic English to German and English to French translation benchmarks.
Transformer neural networks have gained popularity as an alternative to CNNs and RNNs because their "attention mechanism" enables them to capture and process multiple elements in a sequence simultaneously, which is a distinct advantage over other neural network architectures. It is this mechanism that makes transformers highly suitable for complex NLP tasks, such as text translations.
Generative adversarial networks
Generative adversarial networks consist of two neural networks -- a generator and a discriminator -- that compete against each other. The generator creates fake data, while the discriminator evaluates its authenticity. These types of neural networks are widely used for generating realistic images and data augmentation processes.
Advantages of artificial neural networks
Artificial neural networks offer the following benefits:
- Parallel processing. ANNs' parallel processing abilities mean the network can perform more than one job at a time.
- Feature extraction. Neural networks can automatically learn and extract relevant features from raw data, which simplifies the modeling process. However, traditional ML methods differ from neural networks in the sense that they often require manual feature engineering.
- Information storage. ANNs store information on the entire network, not just in a database. This ensures that even if a small amount of data disappears from one location, the entire network continues to operate.
- Nonlinearity. The ability to learn and model nonlinear, complex relationships helps model the real-world relationships between input and output.
- Fault tolerance. ANNs come with fault tolerance, which means the corruption or fault of one or more cells of the ANN won't stop the generation of output.
- Gradual corruption. This means the network slowly degrades over time instead of degrading instantly when a problem occurs.
- Unrestricted input variables. No restrictions are placed on the input variables, such as how they should be distributed.
- Observation-based decisions. ML means the ANN can learn from events and make decisions based on the observations.
- Unorganized data processing. ANNs are exceptionally good at organizing large amounts of data by processing, sorting and categorizing it.
- Ability to learn hidden relationships. ANNs can learn the hidden relationships in data without commanding any fixed relationship. This means ANNs can better model highly volatile data and nonconstant variance.
- Ability to generalize data. The ability to generalize and infer unseen relationships on unseen data means ANNs can predict the output of unseen data.
Disadvantages of artificial neural networks
Their numerous benefits notwithstanding, it's important to note that neural networks also have some drawbacks, including the following:
- Lack of rules. The lack of rules for determining the proper network structure means the appropriate ANN architecture can only be found through trial, error and experience.
- Computationally expensive. Neural networks such as ANNs use many computational resources. Therefore, training neural networks can be expensive and time-consuming, requiring significant processing power and memory. This can be a barrier for organizations with limited resources or those needing real-time processing.
- Hardware dependency. The requirement of processors with parallel processing abilities makes neural networks dependent on hardware.
- Numerical translation. The network works with numerical information, meaning all problems must be translated into numerical values before they can be presented to the ANN.
- Lack of trust. The lack of explanation behind probing solutions is one of the biggest disadvantages of ANNs. The inability to explain the why or how behind the solution generates a lack of trust in the network.
- Inaccurate results. If not trained properly, ANNs can produce incomplete or inaccurate results.
- Black box nature. Because of their black box AI model, it can be challenging to grasp how neural networks make their predictions or categorize data.
- Overfitting. Neural networks are susceptible to overfitting, particularly when trained on small data sets. They can end up learning the noise -- focusing on non-relevant factors such as the typeface in a document -- in the training data instead of the underlying patterns, which can result in poor performance on new and unseen data.
History and timeline of neural networks
The history of neural networks spans several decades and has seen considerable advancements. The following examines the important milestones and developments in the history of neural networks:
- 1940s. In 1943, mathematicians Warren McCulloch and Walter Pitts built a circuitry system that ran simple algorithms and was intended to approximate the functioning of the human brain.
- 1950s. In 1958, Rosenblatt created the perceptron, a form of artificial neural network capable of learning and making judgments by modifying its weights. The perceptron featured a single layer of computing units and could handle problems that were linearly separate.
- 1970s. Paul Werbos, an American scientist, developed the backpropagation method, which facilitated the training of multilayer neural networks. It made deep learning possible by enabling weights to be adjusted across the network based on the error calculated at the output layer.
- 1980s. Cognitive psychologist and computer scientist Geoffrey Hinton, computer scientist Yann LeCun and a group of fellow researchers began investigating the concept of connectionism, which emphasizes the idea that cognitive processes emerge through interconnected networks of simple processing units. This period paved the way for modern neural networks and deep learning models.
- 1990s. Jürgen Schmidhuber and Sepp Hochreiter, both computer scientists from Germany, proposed the long short-term memory recurrent neural network framework in 1997.
- 2000s. Hinton and his colleagues at the University of Toronto pioneered restricted Boltzmann machines, a sort of generative artificial neural network that enables unsupervised learning. RBMs opened the path for deep belief networks and deep learning algorithms.
- 2010s. Research in neural networks picked up great speed around 2010. The big data trend, where companies amassed vast troves of data, and parallel computing gave data scientists the training data and computing resources needed to run complex ANNs. In 2011, Google's speech recognition team discovered that deep learning is a powerful approach for speech recognition. This discovery led to large-scale modifications in Google's Android operating system. In the same year, a collaboration between machine learning researcher Andrew Ng and Googler Jeff Dean led to the development of a massively large unsupervised neural network that offered unprecedented performance on computer vision tasks. In 2012, a neural network named AlexNet won the ImageNet Large Scale Visual Recognition Challenge, an image classification competition. Around this time, researchers at Caltech and elsewhere discovered that graphics processing units (GPUs) could be used to handle the huge computational demands of large/complex neural networks.
- 2020s and beyond. Neural networks continue to undergo rapid development, with advancements in architecture, training methods and applications. Researchers are exploring new network structures such as transformers and graph neural networks, which excel in NLP and understanding complex relationships. Similarly, Kolmogorov-Arnold Networks (KANs) are being studied for applications involving non-linear and interdependent variable relationships, such as weather modeling and fluid dynamics. Additionally, techniques such as transfer learning and self-supervised learning are enabling neural networks and deep learning models to learn from smaller data sets and generalize better. These developments are driving progress in fields such as healthcare, autonomous vehicles, facial recognition, language translations, and wearables.
Discover the process for building a machine learning model, including data collection, preparation, training, evaluation and iteration. Follow these essential steps to kick-start your ML project.







