KLOC (thousands of lines of code)

What is KLOC (thousands of lines of code)?
KLOC (thousands of lines of code) is a traditional measure of how large a computer program is or how long or how many people it will take to write it. The code measured is usually source code.
The KLOC metric is often used when evaluating an application's total number of lines of code (LOC) -- or source lines of code (SLOC). The terms LOC and SLOC are commonly used interchangeably, although some resources distinguish between the two, treating SLOC as a more accurate metric for measuring the amount of code. LOC might also be categorized as either physical LOC or logical LOC. Physical LOC generally refers to the number of lines in a program file, whereas logical LOC is more concerned with the number of statements.
There is little agreement about the exact meaning of these terms or the best way to measure LOC to get an accurate picture of an application's size. Some LOC counts include comments and blank lines (white space), and some do not. Others might include comments but not blank lines, or vice versa. In other cases, LOC might take into account how a statement is spread out across multiple lines. For example, the count might not include a line with a single bracket or curly brace.
GitHub offers one example of how LOC is measured. Example 1 shows a small portion of source code from Tsunami, an Open Source security scanner. The application is written in Java and includes hundreds of files. The figure shows code from one of those files, NetworkEndpointUtils.java. According to GitHub, the file contains 279 physical lines, but only 253 of those are included in the SLOC calculation, leaving 26 lines unaccounted for.
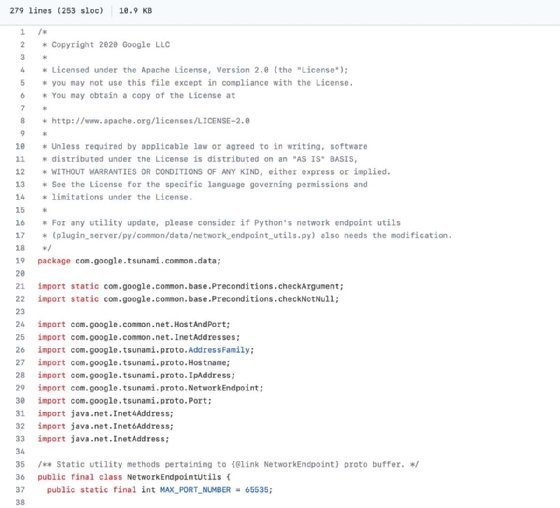
If you scroll through this file, you'll see that it includes 279 physical lines, but 26 lines are blank. This indicates that GitHub includes comments in its SLOC calculations but not blank lines. GitHub also includes lines with only a single curly brace, as well as lines used for a single statement. For example, if a variable assignment spans four lines, GitHub includes all four lines in its SLOC count.
The GitHub approach is by no means a universal standard. GitHub hosts a wide range of applications, so it takes a basic approach to line counts and SLOC, one that can accommodate the various programming languages. Each language supports different syntax, so it can be difficult to apply a single LOC standard across all environments. For example, a logical LOC approach might count the number of statements based on the semicolons used to terminate statements in languages such as Java or C++. However, a language such as Python relies on line ends and indents to indicate different statement logic, not semicolons.
Even when developers are working in the same language, different approaches to development further complicate the use of LOC metrics. Example 2 helps illustrate this issue. The figure shows a simple script that imports the os module, defines a path to a parent directory and then retrieves the subdirectories in the parent directory. The script then lists the name of each subdirectory, along with the number of items it contains. The entire file contains only 12 lines of code, including the comments and blank lines.
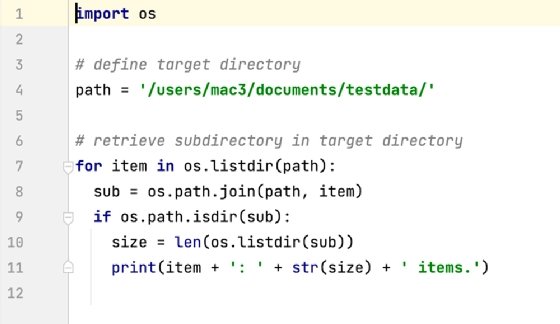
The script raises the question of whether comments and blank lines should be included in the LOC calculations. If they're not included, you would be left with only eight lines of code, including the final blank line. In fact, that's what has been done in the script shown in Example 3. The second script doesn't include comments or extra blank lines, reducing LOC to eight. However, it deliveries the same functionality as the first script but with fewer lines. If this were a large script or part of an application that includes hundreds of files, the difference in LOC could be significant.
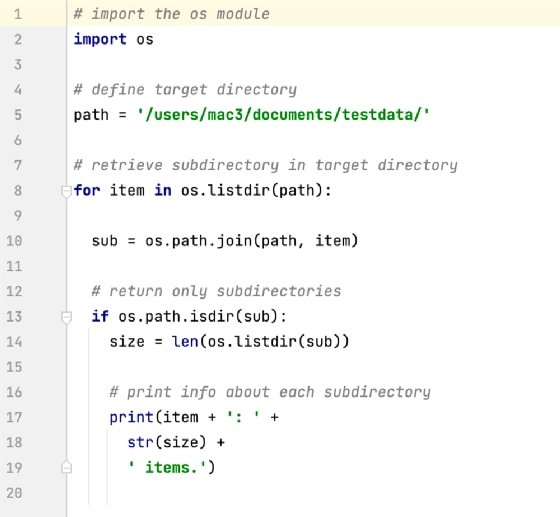
A third developer might take a different approach altogether, this time including more comments and more blank lines. In Example 4, the developer has also broken the print statement into three lines, resulting in total LOC of 20. This is significantly more lines than the code from either the first or second developer, yet the third script delivers the same functionality as the other scripts, only resulting in a lot more lines.
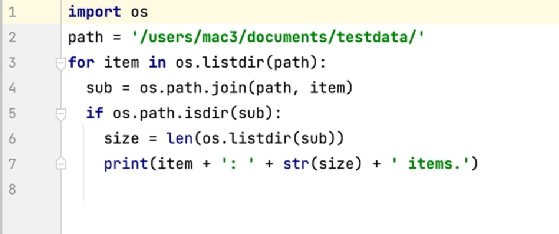
The three Python scripts offer only a simple example in code differences, but they point to the larger challenge with using LOC or KLOC as a metric in measuring an application's size, even if working with a single programming language. Larger applications often use multiple languages, making it even more difficult to arrive at useful LOC counts. Some applications also incorporate autogenerated code, and as with other aspects of LOC counting, there's no clear agreement on whether that code should be included.
LOC and KLOC have often been used to measure programmer productivity, as in: "How many lines of code can you write in a day?" One of the biggest challenges with this approach is that LOC counts do not consider the efficiency of the code. An experienced developer might be able to deliver the same functionality in half the LOC as a novice developer and with fewer errors. If LOC is used as a measure of productivity, the experienced developer might be tempted to pad the code or write substandard code that takes more lines. Many factors can affect productivity, including the complexity of the application. The aim of good programming should be to minimize LOC, not increase it to appease a misguided management directive.
Despite the drawbacks of using LOC as a metric, it can still be useful at times by offering a general overview of the state of development. For example, it can provide development teams with a sense of how their code is evolving over time or how successful they've been in reducing LOC. It can also alert them to potential issues if there's a dramatic change in LOC. In addition, it can be used when evaluating code quality by measuring the number of defects per KLOC. Whenever LOC or KLOC are used, however, it should be done with their limitations in mind.
Check out Python code formatting tools you need and why it matters, and explore 23 software development metrics.