reliability of computers

What is reliability of computers?
Reliability is an attribute of any computer-related component -- software, hardware or a network, for example -- that consistently performs according to its specifications. It has long been considered one of three related attributes that must be considered when making, buying or using a computer product or component.
Reliability is a key consideration when buying computer products. Computer system and component manufacturers and software developers often highlight it as an attribute of their products. The more upgrades and updates a product has undergone, the more likely it is that problems have been addressed, making it more reliable.
How does reliability work?
Reliability takes many forms. A reliable computer exhibits dependability and has high uptime and low downtime and system failure rates. System reliability can be achieved using techniques such as redundancy.
Redundant systems have multiple copies of critical components available. That way, if a primary component fails, a backup can be used. Redundant systems also have fault tolerance, which is the ability of a computing device to absorb a disruptive event, such as a power outage, and quickly resume operation and output.
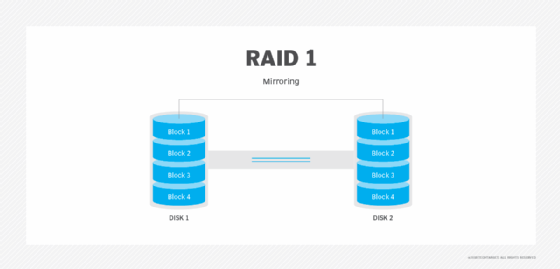
Reliability, availability and serviceability are important aspects to design into a system. In computer science and computer systems theory, a reliable product is free of technical errors; in practice, however, vendors frequently express a product's reliability quotient as a percentage.
Evolutionary products -- those that providers have evolved through numerous versions over time -- are thought to become increasingly reliable as bugs are eliminated in each subsequent release. For example, IBM's z/OS, an operating system for its S/390 server series, has a reputation for being reliable. It evolved from a long line of earlier Multiple Virtual Storage and OS/390 versions.
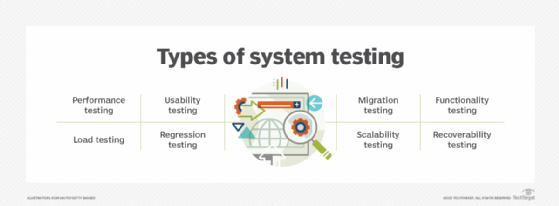
What metrics can demonstrate reliability?
Various metrics are used to measure computing system reliability and the probability of failure, including the following:
System availability
This is the ratio of a system's actual operating time divided by the total amount of time it should be available, which is its uptime plus its downtime. The closer to 1 that number is, the better its availability and the more reliable it is because that would be equivalent to 100% availability.
System availability = Total uptime ÷ (Total uptime + Total downtime)
For example, a server runs for 500 hours before having an issue that takes 10 hours to repair. It then runs another 970 hours before having another issue that takes 20 hours to repair. Its system availability is the total operating time of 1,470 hours divided by the total time the server should have been available, which was 1,500 hours. That equals 0.98, meaning the server was available 98% of the time.
Mean time between failures (MTBF)
This is the average amount of time between system or component failures. To calculate MTBF, divide a system's total operating time by the number of downtime incidents. This metric is used for repairable systems or components.
MTBF = Total uptime ÷ Number of downtime incidents
The MTBF for the server discussed above would be the total uptime of 1,470 hours divided by two incidents, making the MTBF 735 hours.
Mean time to repair (MTTR)
This measures how fast a disabled or failed component can be returned to normal operations. MTTR is calculated by taking the total downtime a system experiences in a given time period and dividing it by the number of downtime incidents. The faster a system or component can be repaired, the lower the MTTR.
MTTR = Total downtime ÷ Number of downtime incidents
In the server example, the MTTR would be the 30 hours of downtime divided by the two incidents, equaling 15 hours.
Mean time to failure (MTTF)
This is the average period of time a nonrepairable system or component will run before it fails. This is only used for systems or parts that can't or aren't going to be repaired. In most organizations, it wouldn't apply to the server example; it's more likely to apply to a part such as a lightbulb that would be replaced rather than repaired. It's calculated by adding the total operating time before failure of several lightbulbs and dividing that total by the number of lightbulbs being assessed.
MTTF = Total hours of operation ÷ Total number of assets in use
How is reliability tested and verified?
Many diagnostic and testing tools are available to measure the reliability of systems and networks. Checking manufacturer reports on a device's performance can provide good information on its reliability. User and third-party assessments are also a good way to get insight.
Manufacturers continue to do reliability testing and validation even after a system or device goes into production. IT system and software engineering teams also do ongoing quality management activities. Third-party companies experienced in reliability testing can also be employed for these assessments.
During software development, a key part of the process is to regularly test the software to make sure it performs as designed and is reliable. Running applications continuously for a period is one test. Another is to send many inquiries to the software to see how it reacts.

What organization sets computer reliability standards?
The Institute of Electrical and Electronics Engineers, or IEEE, Reliability Society is an organization devoted to reliability in engineering. It promotes a systematic approach to design that fosters reliability in engineering, maintenance and analysis.
The Reliability Society encourages collaborative effort and information sharing among members. The various industries represented in the group include aerospace, transportation systems, medical electronics, computers, telecommunications and other areas of engineering.
Various associations and governmental bodies provide input into product reliability in specific industries. For example, the International Automotive Task Force plays such a role in the automotive industry.
Tips for ensuring technology reliability
The following are ways to ensure systems, networks and software perform as reliably as possible:
- Get IT leadership support for reliability programs.
- Allocate sufficient funding for reliability testing in budgets.
- Set up schedules for regular testing.
- Identify resources to keep systems functioning at optimal levels, such as spare parts, backup power systems, and backup of data and software.
- Document all reliability testing activities and compare previous reports with current performance to identify opportunities for improvement.
- Conduct periodic risk assessments to identify potential threats and vulnerabilities that could affect system reliability.
- Ensure disaster recovery plans contain information on how to recover and restart critical systems in an emergency.
Learn about device reliability engineering and how it promotes product reliability.