vector search

What is vector search?
Vector search, sometimes referred to as vector similarity search, is a technique that uses vectors -- numerical representations of data -- as the basis to conduct searches and identify relevance.
A vector, in the context of a vector search, is defined as a set of numbers mathematically computed and designed to represent data across multiple dimensions. The data that a vector represents can be text, an image or audio. So, instead of a keyword search executed with, for example, traditional search engine technology, the search is done on the vectors, or numbers, to resolve queries.
Securing accurate results is among the foundational goals of vector search. Precise vector searches support document and data search use cases. Vector search is also widely used in artificial intelligence (AI) and machine learning (ML), as well as to support other use cases such as chatbots, recommendation systems and retrieval-augmented generation (RAG).
The basic concepts behind vector search date to 1974, when Cornell University researchers published "A Vector Space Model for Automatic Indexing," defining its early foundations. Continued research through subsequent decades advanced the original concepts and introduced methods to achieve high levels of search accuracy.
In 2013, researchers Tomas Mikolov, Kai Chen, Greg Corrado and Jeffrey Dean published "Efficient Estimation of Word Representations in Vector Space," which advanced the concept of converting words into vectors. With the introduction of transformer models in 2017, vector search usage continues to expand in both search and AI deployments.
How does vector search work?
Vectors contain multidimensional data, where each dimension in the vector space defines a specific attribute or feature of its data. The key concept is that semantically similar data points are closer to each other within vector space.
To enable vector search, the first step is to convert data from its native form into vector representations, commonly referred to as vector embeddings, or just embeddings. Here, real-world objects -- words, sentences or images -- are mapped as numbers that capture the meaningful properties and relationships of these objects.
Once vector embeddings are created, the vectors are typically stored in a vector database. Purpose-built vector databases, such as Pinecone or Milvus, provide efficient storage and retrieval of vector data. Vector support is also increasingly finding its way into more general-purpose multimodel database platforms. Rockset, MongoDB, Neo4j and Oracle were among the database vendors that added vector support in 2023 alongside other data types.
There are several vector search algorithms used to find vectors in the database that are most similar, or closest, to the query vector. Among the commonly used algorithms are approximate nearest neighbor and K-nearest neighbor; both use mathematical techniques to compute the similarity among and proximity between vectors with varying degrees of precision. Another approach used to determine vector relevance is cosine similarity, which provides methods to determine relationships across two vectors.
The most relevant vector results represent the data points that are closest semantically to the search query, even if those data points don't match the query exactly. This allows vector search to uncover less obvious relationships than keyword matching. Re-ranking and filtering can further refine and improve the results.
What are vector embeddings?
Vector embeddings are a foundational enabling element of vector search.
Embeddings are representations of various forms of data as lists of numbers. This numerical representation captures the meaningful properties and relationships of the objects. Further, it provides this information in a format that underpins a highly accurate search query assessing semantic similarity through mathematical operations.
The vector embedding process involves mapping objects such as words into a set of numbers. Machine learning techniques such as neural networks generate these embeddings by analyzing large data sets to uncover patterns. The dimensionality of the embeddings determines how much semantic information can be encoded. Since each dimension encodes a unique attribute of the object, more dimensions enable more nuanced representations.
Created models identify how to represent objects in a distributed vector space, where distance corresponds to semantic similarity. For example, embeddings could represent that the words cat and feline are closer together in vector space than cat and car. The vectors capture these relationships in the dimensions learned from data patterns.
Vector embeddings provide a mathematically convenient common format for encoding meaningful properties of objects based on large data analysis. There are many different technologies for creating vector embeddings. Among the most popular are the ada text embedding models from OpenAI, the vendor behind the ChatGPT service. Google's gecko embedding models are also widely used as part of the company's Vertex AI service.
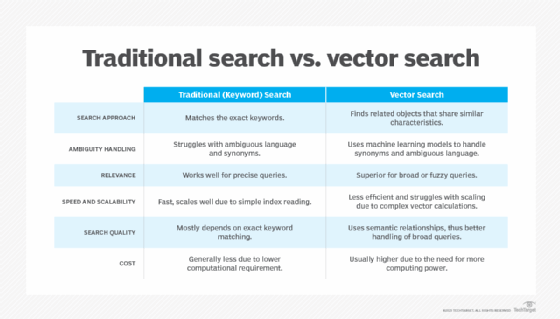
Traditional vs. vector search
There are several key differences between traditional search techniques and vector search.
In traditional keyword search, documents are indexed based on the words they contain. Queries are matched to documents containing those exact keywords. However, this approach does not capture semantic meaning. Returning to the previous example, a document about felines might indeed be relevant to a query for cats, but it could be missed by a keyword search.
With vector search, embedding captures multiple dimensions to determine any semantic association. In fact, a key advantage of vector similarity is overcoming word ambiguity.
Vector search use cases
Vector search is applicable across a wide swath of use cases that meet various needs in a variety of fields. The following are among the most common vector search use cases:
- Recommendation engines. Vector search enables more accurate recommendation engines, including those used on e-commerce sites for personalization. User preferences and profiles, along with products and content, are encoded as vectors. Recommendations can be generated by finding vectors closest to the user's interests.
- Semantic search and content discovery. Powering semantic search is another common use case because keyword-based searches struggle with synonyms, but vector similarity addresses this by capturing meaning.
- Natural language processing (NLP). Vector search is central to the use of NLP, which is used in multiple applications, including chatbots. It allows users to interact directly with systems by asking questions that are vectorized and matched to their nearest neighbors.
- Anomaly detection. For security and fraud detection, vector search identifies data points deviating from baseline vectors that represent normal data.
- Drug discovery. It's also useful for drug discovery, allowing researchers to find chemical compounds with similar molecular vector representations to existing drugs.
- Genomics. Understanding the functional associations between genes using vector embeddings of sequencing data aids genomics research.
- Duplicate detection. Nearby duplicate vector representations remove redundancies.
- Image search. Looking beyond text, vector search allows users to find visually or semantically similar images based on vector encoding of image properties.
- Keyword expansion. Vector search, used alongside traditional search, suggests additional keyword queries based on similarity between term vectors.
- Retrieval-augmented generation. RAG enables a higher degree of accuracy from a large language model by pulling data sourced from vector search techniques.
Vector search benefits
Vector search improves the depth and breadth of searching and querying different types of data. The benefits of vector search include the following:
- Optimized unstructured data search. Vector search allows applications, users and AI models to efficiently query and browse unstructured data. This capability is crucial in dealing with modern data types such as images, videos and text embeddings.
- Contextual meaning to data. Vector search doesn't just match keywords. Instead, it recognizes the context of the query, often providing a more relevant result.
- Semantic understanding to queries. By representing data points as vectors, vector search adds a deeper, semantic understanding to queries, leading to a more accurate result on a per-user basis.
- More relevant results. Beyond the additional context and semantic capabilities, the nearest-neighbor vector approach identifies data that is most similar to the query.
- Integration with machine learning frameworks. Vector search is increasingly tied to AI and ML because models can benefit from vector search to help generate content.
Vector search limitations
Despite all the benefits that it provides, there are current limitations to and challenges for vector search, including the following:
- Speed and scalability. The complex vector computations required for similarity scoring require more computing power, which can create a performance bottleneck.
- Resource intensive. Generating and storing vector embeddings requires significantly more resources than a keyword-based approach.
- Accuracy vs. keyword search. For some targeted queries, vector search returns less precise results compared with keyword search, which is often superior for very intentional, precise lookups.
- Explainability challenges. Sharing vector similarity and relevance is typically more difficult than explaining relevance with a simple keyword search.