LZW compression

What is LZW compression?
LZW compression is a method to reduce the size of Tag Image File Format (TIFF) or Graphics Interchange Format (GIF) files. It is a table-based lookup algorithm to remove duplicate data and compress an original file into a smaller file. LZW compression is also suitable for compressing text and PDF files. The algorithm is loosely based on the LZ78 algorithm that was developed by Abraham Lempel and Jacob Ziv in 1978.
Invented by Abraham Lempel, Jacob Ziv and Terry Welch in 1984, the LZW compression algorithm is a type of lossless compression. Lossless algorithms reduce bits in a file by removing statistical redundancy without causing information loss. This makes LZW -- and other lossless algorithms, like ZIP -- different from lossy compression algorithms that reduce file size by removing less important or unnecessary information and cause information loss.
The LZW algorithm is commonly used to compress GIF and TIFF image files and occasionally for PDF and TXT files. It is part of the Unix operating system's file compression utility. The method is simple to implement, versatile and capable of high throughput in hardware implementations. Consequently, LZW is often used for general-purpose data compression in many PC utilities.

How LZW compression works
The LZW compression algorithm reads a sequence of symbols, groups those symbols into strings and then converts each string into codes. It takes each input sequence of bits of a given length -- say, 12 bits -- and creates an entry in a table for that particular bit pattern, consisting of the pattern itself and a shorter code. The table is also called a dictionary or codebook. It stores character sequences chosen dynamically from the input text and maintains correspondence between the longest encountered words and a list of code values.
As the input is read, any repetitive results are substituted with the shorter code, effectively compressing the total amount of input. The shorter code takes up less space than the string it replaces, resulting in a smaller file. As the number of long, repetitive words increases in the input data, the algorithm's efficiency also increases. Compression occurs when the output is a single code instead of a longer string of characters. This code can be of any length and always has more bits than a single character.
The LZW algorithm does not analyze the incoming text. It simply adds every new string of characters it sees into a code table. Since it tries to recognize increasingly longer and repetitive phrases and encode them, LZW is referred to as a greedy algorithm.

Code table in LZW compression
Unlike earlier approaches, such as LZ77 and LZ78, the LZW algorithm includes a lookup table of codes as part of the compressed file. Typically, the number of table entries is 4,096. In the code table, codes 0-255 are assigned to represent single bytes from the input file. Before the algorithm starts encoding, the table contains only the first 256 entries. The rest of the table is blank. In other words, the first 256 codes are assigned to the standard character set by default.
The remaining codes are assigned to strings as the algorithm proceeds with the compression. When encoding starts, the algorithm identifies repeated sequences in the data and adds them to the code table so that it fills up with more entries. For file compression, codes 256 through 4,095 are used to represent sequences of bytes. These codes refer to substrings, while codes 0-255 refer to individual bytes.
The decoding program that decompresses the file can build the table by using the algorithm as it processes the encoded input. It takes each code from the compressed file and translates it through the code table that's being built to find the character that code represents.
Advantages and drawbacks of LZW compression
The LZW algorithm quickly compresses large TIFF or GIF files. It works especially well for files containing a lot of repetitive data, which is common with monochrome images.
One drawback of LZW compression is that compressed files without repetitive information can be large, defeating the purpose of compression. Another issue is that some versions of the algorithm are copyrighted, so companies must pay royalties or licensing fees to use it. These fees may get added to the product cost.
Finally, LZW is not the most efficient compression algorithm. Other algorithms are available to compress files faster and more efficiently.
LZW compression vs. ZIP compression
LZW and ZIP are both lossless compression methods, meaning no data is lost after compression. TIFF files retain their quality after being compressed into smaller files using either LZW or ZIP. That said, compressed TIFF files can be slightly slower to work with because they require more processing effort to open and close them.
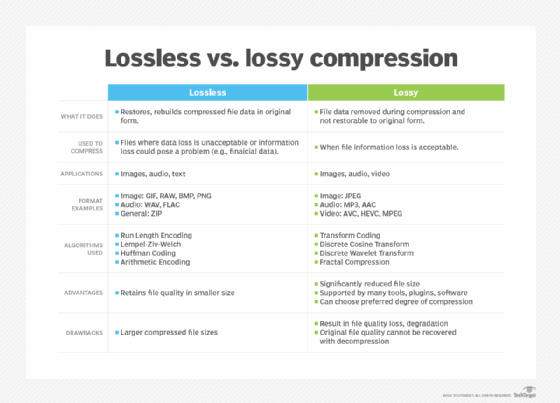
LZW and ZIP provide good results with 8-bit TIFF files. For 16-bit TIFF files, the ZIP algorithm performs better than LZW. In fact, LZW tends to make 16-bit files larger. Generally, both algorithms work efficiently when they can group a lot of similar data and work on images that are low on detail and contain few tones. These images compress more than images containing lots of detail or different tones.
Explore the differences among compression vs. deduplication vs. encryption.